 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny, On-Device Decision Makers with the MiniConv Library
Paper and Code
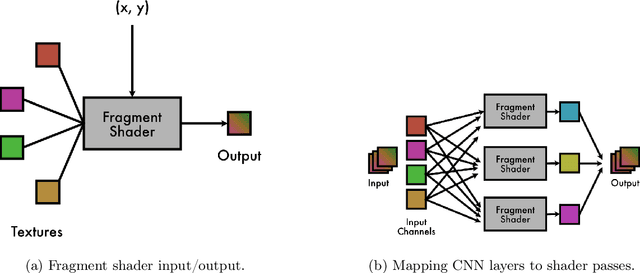

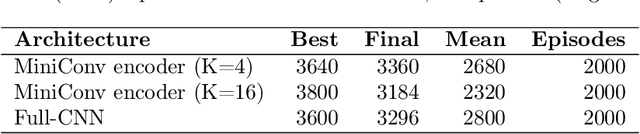
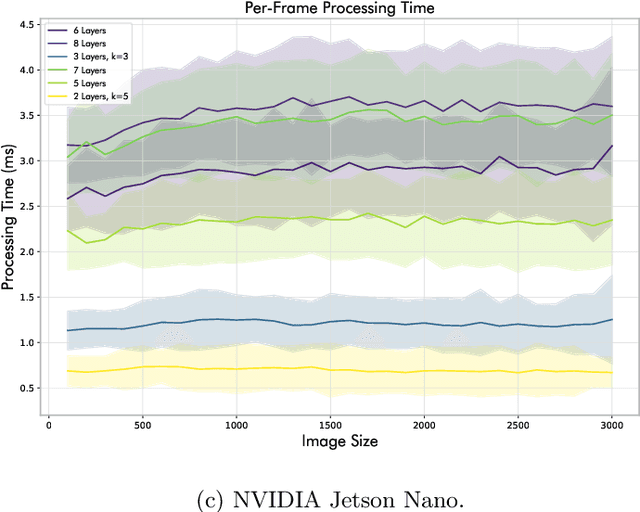
Reinforcement learning (RL) has achieved strong results, but deploying visual policies on resource-constrained edge devices remains challenging due to computational cost and communication latency. Many deployments therefore offload policy inference to a remote server, incurring network round trips and requiring transmission of high-dimensional observations. We introduce a split-policy architecture in which a small on-device encoder, implemented as OpenGL fragment-shader passes for broad embedded GPU support, transforms each observation into a compact feature tensor that is transmitted to a remote policy head. In RL, this communication overhead manifests as closed-loop decision latency rather than only per-request inference latency. The proposed approach reduces transmitted data, lowers decision latency in bandwidth-limited settings, and reduces server-side compute per request, whilst achieving broadly comparable learning performance by final return (mean over the final 100 episodes) in single-run benchmarks, with modest trade-offs in mean return. We evaluate across an NVIDIA Jetson Nano, a Raspberry Pi 4B, and a Raspberry Pi Zero 2 W, reporting learning results, on-device execution behaviour under sustained load, and end-to-end decision latency and scalability measurements under bandwidth shaping. Code for training, deployment, and measurement is released as open source.