 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic regression outperforms other models for small data sets
Paper and Code
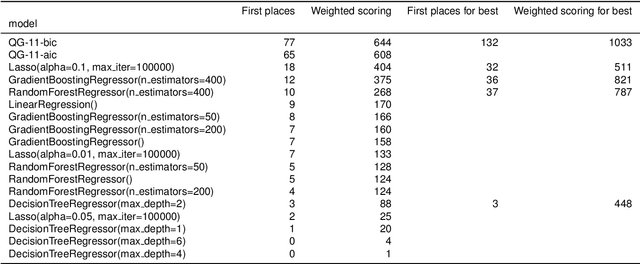
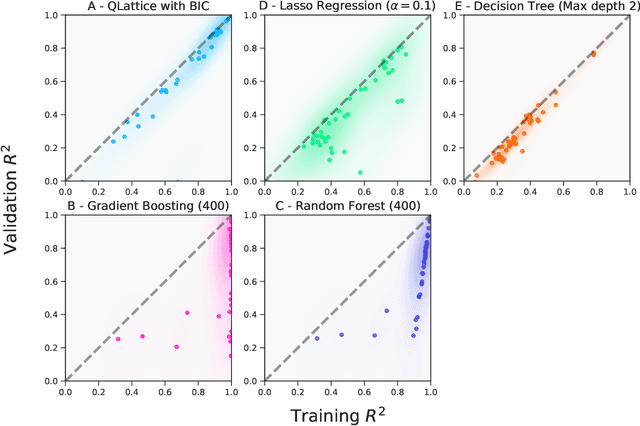
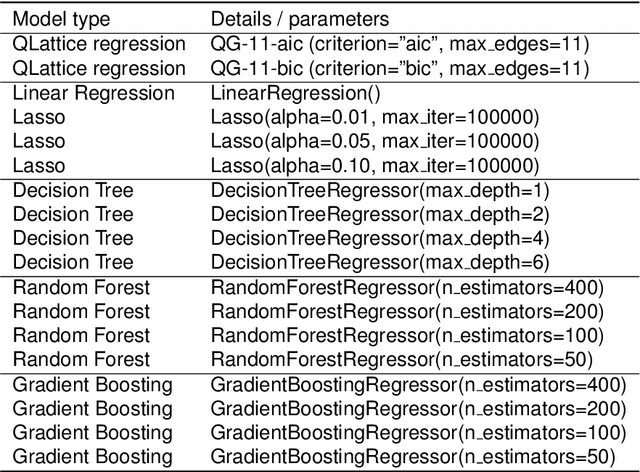
Machine learning is often applied to obtain predictions and new understandings of complex phenomena and relationships, but an availability of sufficient data for model training is a widespread problem. Traditional machine learning techniques, such as random forests and gradient boosting, tend to overfit when working with data sets of only a few hundred observations. This study demonstrates that for small training sets of 250 observations, symbolic regression generalises better to out-of-sample data than traditional machine learning frameworks, as measured by the coefficient of determination $R^2$ on the validation set. In 132 out of 240 cases, symbolic regression achieves a higher $R^2$ than any of the other models on the out-of-sample data. Furthermore, symbolic regression also preserves the interpretability of linear models and decision trees, an added benefit to its superior generalization. The second best algorithm was found to be a random forest, which performs best in 37 of the 240 cases. When restricting the comparison to interpretable models, symbolic regression performs best in 184 out of 240 cases.