 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Enforcement of Instruction Hierarchy via Augmented Intermediate Representations
Paper and Code

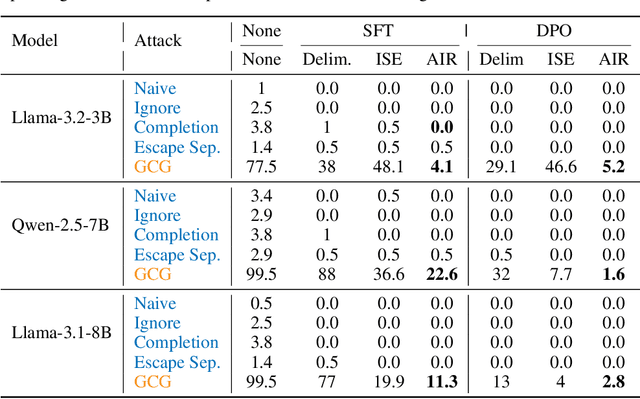
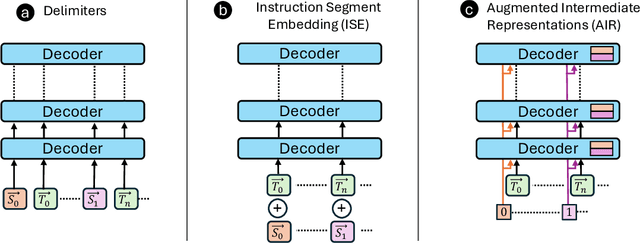
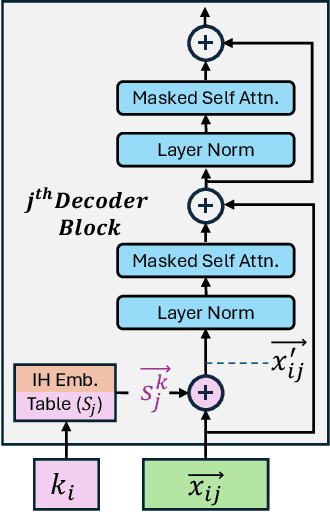
Prompt injection attacks are a critical security vulnerability in large language models (LLMs), allowing attackers to hijack model behavior by injecting malicious instructions within the input context. Recent defense mechanisms have leveraged an Instruction Hierarchy (IH) Signal, often implemented through special delimiter tokens or additive embeddings to denote the privilege level of input tokens. However, these prior works typically inject the IH signal exclusively at the initial input layer, which we hypothesize limits its ability to effectively distinguish the privilege levels of tokens as it propagates through the different layers of the model. To overcome this limitation, we introduce a novel approach that injects the IH signal into the intermediate token representations within the network. Our method augments these representations with layer-specific trainable embeddings that encode the privilege information. Our evaluations across multiple models and training methods reveal that our proposal yields between $1.6\times$ and $9.2\times$ reduction in attack success rate on gradient-based prompt injection attacks compared to state-of-the-art methods, without significantly degrading the model's utility.