 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Pooled Time Series of Big Video Data from the Deep Web
Paper and Code
Oct 21, 2016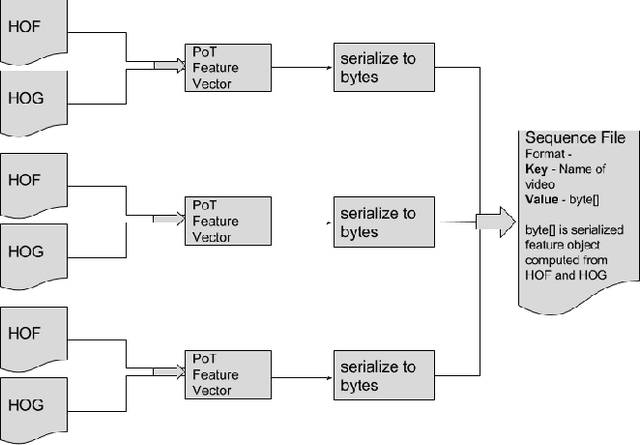
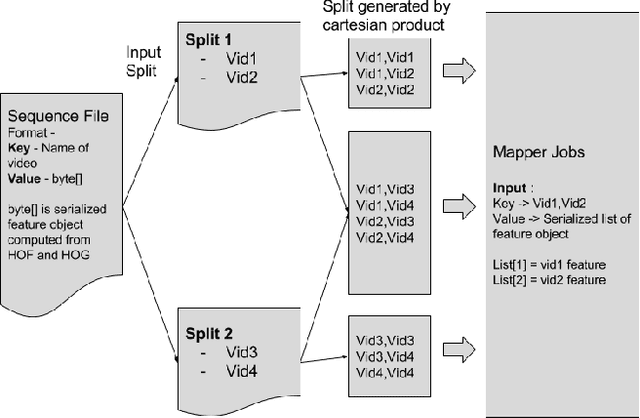

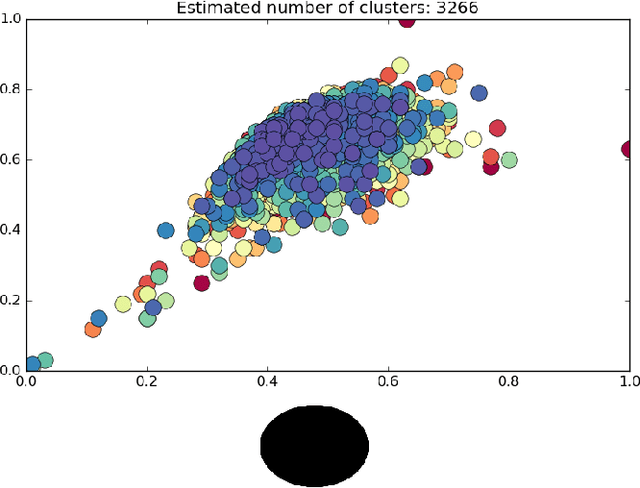
We contribute a scalable implementation of Ryoo et al's Pooled Time Series algorithm from CVPR 2015. The updated algorithm has been evaluated on a large and diverse dataset of approximately 6800 videos collected from a crawl of the deep web related to human trafficking on DARPA's MEMEX effort. We describe the properties of Pooled Time Series and the motivation for using it to relate videos collected from the deep web. We highlight issues that we found while running Pooled Time Series on larger datasets and discuss solutions for those issues. Our solution centers are re-imagining Pooled Time Series as a Hadoop-based algorithm in which we compute portions of the eventual solution in parallel on large commodity clusters. We demonstrate that our new Hadoop-based algorithm works well on the 6800 video dataset and shares all of the properties described in the CVPR 2015 paper. We suggest avenues of future work in the project.