Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
Paper and Code
Nov 24, 2019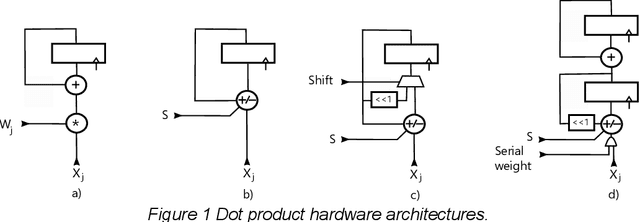


This paper discusses three basic blocks for the inference of convolutional neural networks (CNNs). Pyramid Vector Quantization (PVQ) is discussed as an effective quantizer for CNNs weights resulting in highly sparse and compressible networks. Properties of PVQ are exploited for the elimination of multipliers during inference while maintaining high performance. The result is then extended to any other quantized weights. The Tiny Yolo v3 CNN is used to compare such basic blocks.
View paper on