 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjected Hamming Dissimilarity for Bit-Level Importance Coding in Collaborative Filtering
Paper and Code
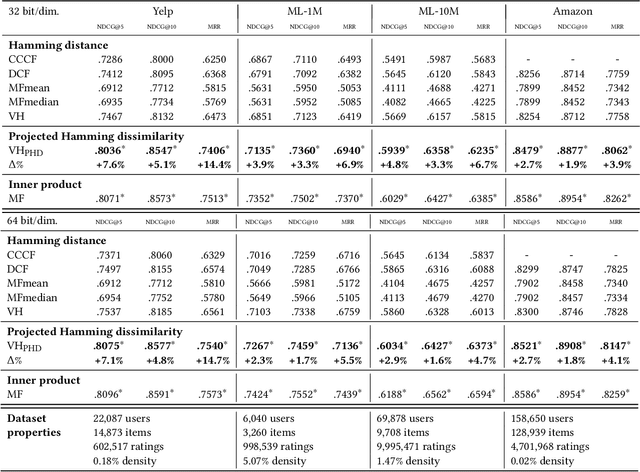
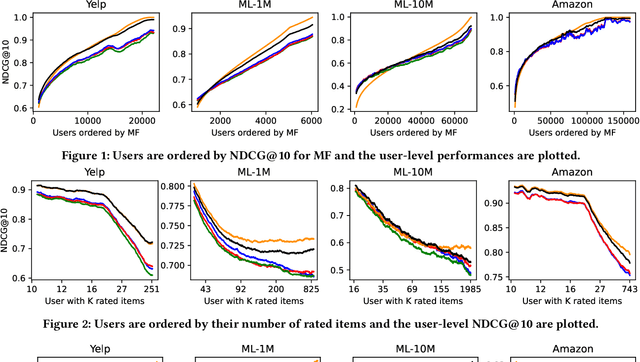
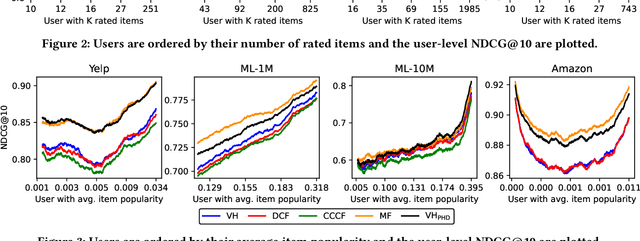
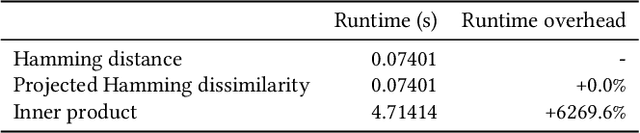
When reasoning about tasks that involve large amounts of data, a common approach is to represent data items as objects in the Hamming space where operations can be done efficiently and effectively. Object similarity can then be computed by learning binary representations (hash codes) of the objects and computing their Hamming distance. While this is highly efficient, each bit dimension is equally weighted, which means that potentially discriminative information of the data is lost. A more expressive alternative is to use real-valued vector representations and compute their inner product; this allows varying the weight of each dimension but is many magnitudes slower. To fix this, we derive a new way of measuring the dissimilarity between two objects in the Hamming space with binary weighting of each dimension (i.e., disabling bits): we consider a field-agnostic dissimilarity that projects the vector of one object onto the vector of the other. When working in the Hamming space, this results in a novel projected Hamming dissimilarity, which by choice of projection, effectively allows a binary importance weighting of the hash code of one object through the hash code of the other. We propose a variational hashing model for learning hash codes optimized for this projected Hamming dissimilarity, and experimentally evaluate it in collaborative filtering experiments. The resultant hash codes lead to effectiveness gains of up to +7% in NDCG and +14% in MRR compared to state-of-the-art hashing-based collaborative filtering baselines, while requiring no additional storage and no computational overhead compared to using the Hamming distance.