 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Visual Context for Unsupervised Event Segmentation in Continuous Photo-streams
Paper and Code
Aug 07, 2018
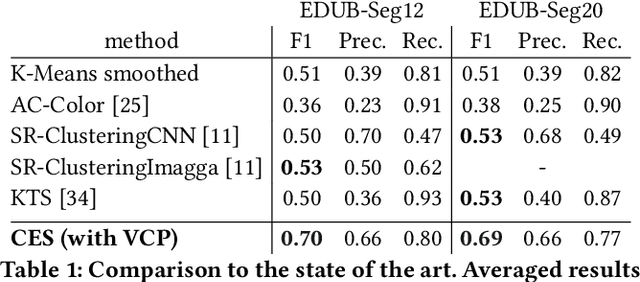
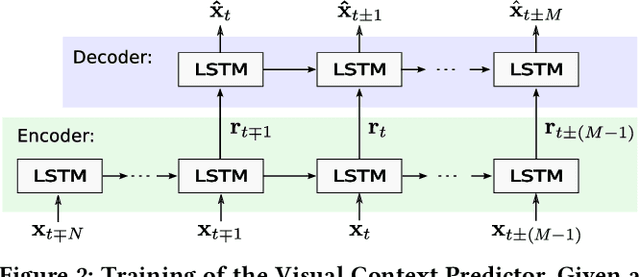

Segmenting video content into events provides semantic structures for indexing, retrieval, and summarization. Since motion cues are not available in continuous photo-streams, and annotations in lifelogging are scarce and costly, the frames are usually clustered into events by comparing the visual features between them in an unsupervised way. However, such methodologies are ineffective to deal with heterogeneous events, e.g. taking a walk, and temporary changes in the sight direction, e.g. at a meeting. To address these limitations, we propose Contextual Event Segmentation (CES), a novel segmentation paradigm that uses an LSTM-based generative network to model the photo-stream sequences, predict their visual context, and track their evolution. CES decides whether a frame is an event boundary by comparing the visual context generated from the frames in the past, to the visual context predicted from the future. We implemented CES on a new and massive lifelogging dataset consisting of more than 1.5 million images spanning over 1,723 days. Experiments on the popular EDUB-Seg dataset show that our model outperforms the state-of-the-art by over 16% in f-measure. Furthermore, CES' performance is only 3 points below that of human annotators.