 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeek Inside the Closed World: Evaluating Autoencoder-Based Detection of DDoS to Cloud
Paper and Code
Dec 16, 2019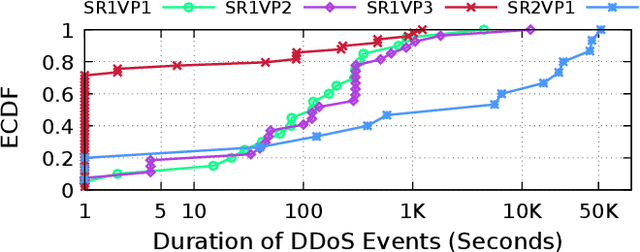

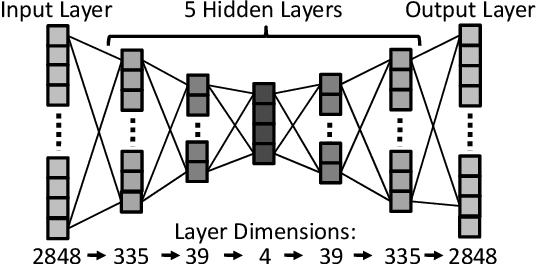

Machine-learning-based anomaly detection (ML-based AD) has been successful at detecting DDoS events in the lab. However published evaluations of ML-based AD have only had limited data and have not provided insight into why it works. To address limited evaluation against real-world data, we apply autoencoder, an existing ML-AD model, to 57 DDoS attack events captured at 5 cloud IPs from a major cloud provider. To improve our understanding for why ML-based AD works or not works, we interpret this data with feature attribution and counterfactual explanation. We show that our version of autoencoders work well overall: our models capture nearly all malicious flows to 2 of the 4 cloud IPs under attacks (at least 99.99%) but generate a few false negatives (5% and 9%) for the remaining 2 IPs. We show that our models maintain near-zero false positives on benign flows to all 5 IPs. Our interpretation of results shows that our models identify almost all malicious flows with non-whitelisted (non-WL) destination ports (99.92%) by learning the full list of benign destination ports from training data (the normality). Interpretation shows that although our models learn incomplete normality for protocols and source ports, they still identify most malicious flows with non-WL protocols and blacklisted (BL) source ports (100.0% and 97.5%) but risk false positives. Interpretation also shows that our models only detect a few malicious flows with BL packet sizes (8.5%) by incorrectly inferring these BL sizes as normal based on incomplete normality learned. We find our models still detect a quarter of flows (24.7%) with abnormal payload contents even when they do not see payload by combining anomalies from multiple flow features. Lastly, we summarize the implications of what we learn on applying autoencoder-based AD in production.