Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Confident UCB: Improved Regret for Finite-Armed Bandits
Paper and Code
Feb 24, 2016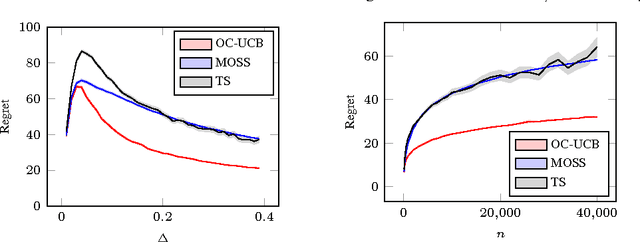
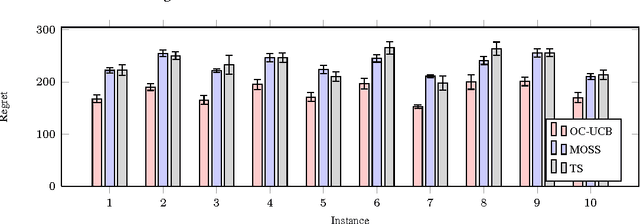
I present the first algorithm for stochastic finite-armed bandits that simultaneously enjoys order-optimal problem-dependent regret and worst-case regret. Besides the theoretical results, the new algorithm is simple, efficient and empirically superb. The approach is based on UCB, but with a carefully chosen confidence parameter that optimally balances the risk of failing confidence intervals against the cost of excessive optimism.
* 26 pages
View paper on