 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAT: Learning to Attack Neurons for Enhanced Adversarial Transferability
Paper and Code
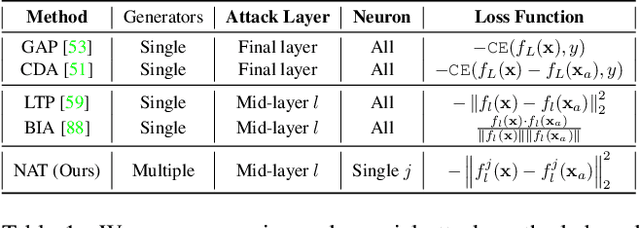
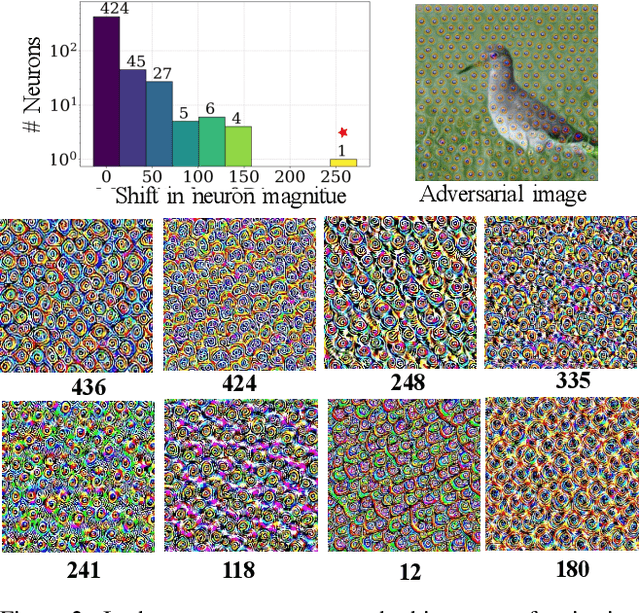
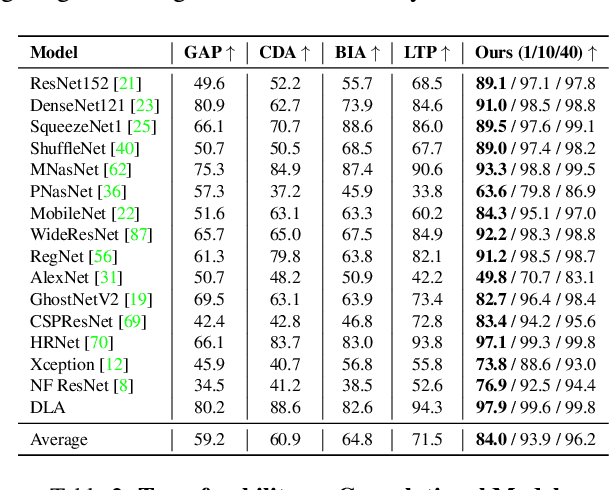
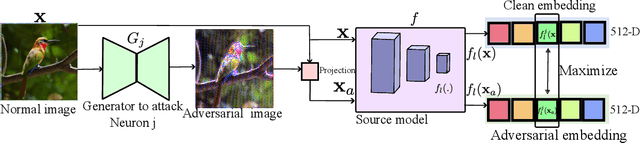
The generation of transferable adversarial perturbations typically involves training a generator to maximize embedding separation between clean and adversarial images at a single mid-layer of a source model. In this work, we build on this approach and introduce Neuron Attack for Transferability (NAT), a method designed to target specific neuron within the embedding. Our approach is motivated by the observation that previous layer-level optimizations often disproportionately focus on a few neurons representing similar concepts, leaving other neurons within the attacked layer minimally affected. NAT shifts the focus from embedding-level separation to a more fundamental, neuron-specific approach. We find that targeting individual neurons effectively disrupts the core units of the neural network, providing a common basis for transferability across different models. Through extensive experiments on 41 diverse ImageNet models and 9 fine-grained models, NAT achieves fooling rates that surpass existing baselines by over 14\% in cross-model and 4\% in cross-domain settings. Furthermore, by leveraging the complementary attacking capabilities of the trained generators, we achieve impressive fooling rates within just 10 queries. Our code is available at: https://krishnakanthnakka.github.io/NAT/