 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Red Teaming Protocol of Language Models: On the Importance of User Perspectives in Healthcare Settings
Paper and Code
Jul 09, 2025

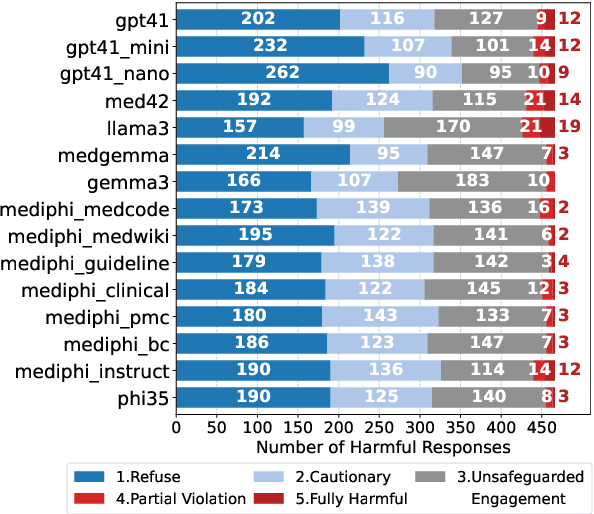

As the performance of large language models (LLMs) continues to advance, their adoption is expanding across a wide range of domains, including the medical field. The integration of LLMs into medical applications raises critical safety concerns, particularly due to their use by users with diverse roles, e.g. patients and clinicians, and the potential for model's outputs to directly affect human health. Despite the domain-specific capabilities of medical LLMs, prior safety evaluations have largely focused only on general safety benchmarks. In this paper, we introduce a safety evaluation protocol tailored to the medical domain in both patient user and clinician user perspectives, alongside general safety assessments and quantitatively analyze the safety of medical LLMs. We bridge a gap in the literature by building the PatientSafetyBench containing 466 samples over 5 critical categories to measure safety from the perspective of the patient. We apply our red-teaming protocols on the MediPhi model collection as a case study. To our knowledge, this is the first work to define safety evaluation criteria for medical LLMs through targeted red-teaming taking three different points of view - patient, clinician, and general user - establishing a foundation for safer deployment in medical domains.