 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning relevant features for statistical inference
Paper and Code
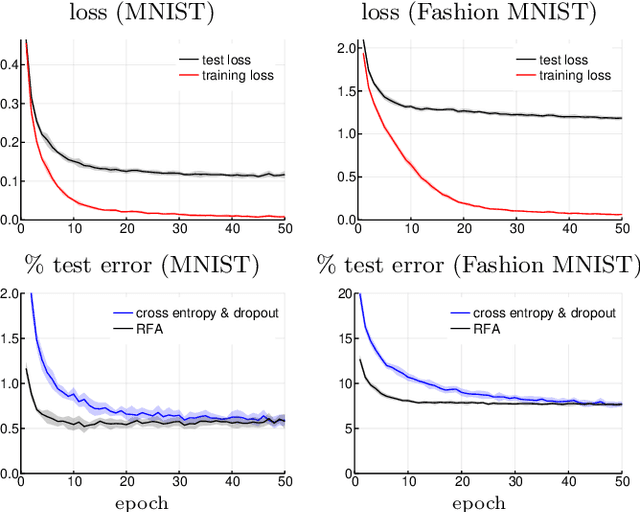

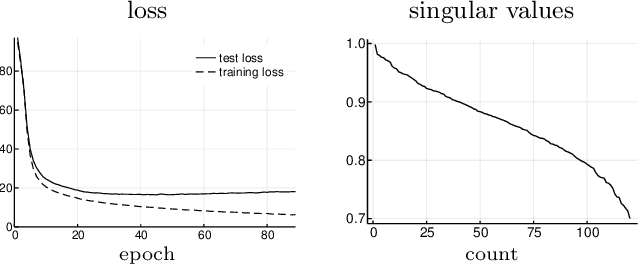

We introduce an algorithm that learns correlations between two datasets, in a way which can be used to infer one type of data given the other. The approach allows for the computation of expectation values over the inferred conditional distributions, such as Bayesian estimators and their standard deviations. This is done by learning feature maps which span hyperplanes in the spaces of probabilities for both types of data, optimized to optimally represent correlations. When applied to supervised learning, this yields a new objective function which automatically provides regularization and results in faster convergence. We propose that, in addition to many applications where two correlated variables appear naturally, this approach could also be used to identify dominant independent features of a single dataset in an unsupervised fashion: in this scenario, the second variables should be produced from the original data by adding noise in a manner which defines an appropriate information metric.