Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Beyond Limits: Multitask Learning and Synthetic Data for Low-Resource Canonical Morpheme Segmentation
Paper and Code
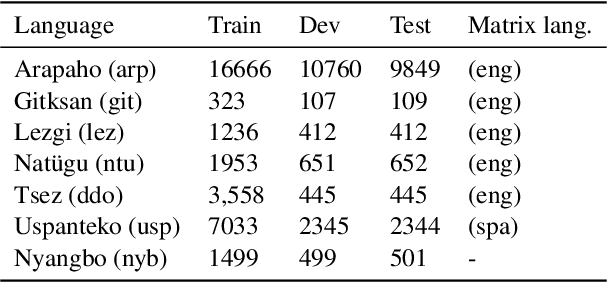
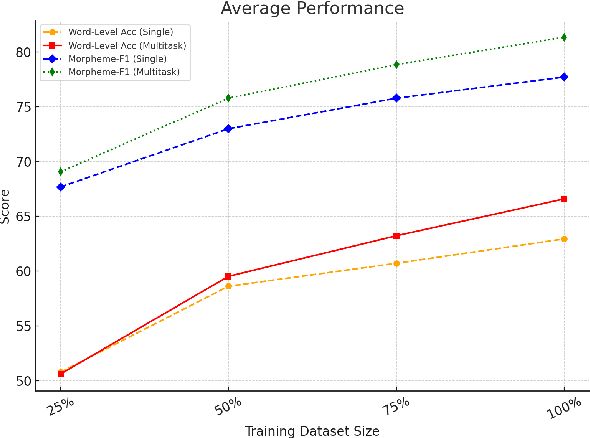
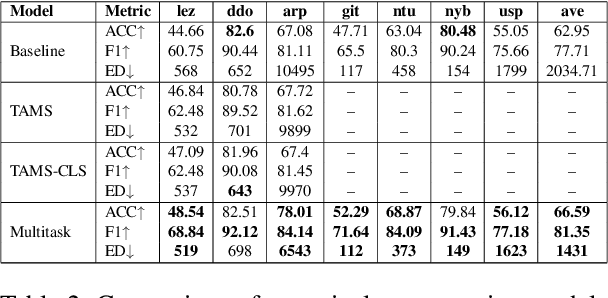
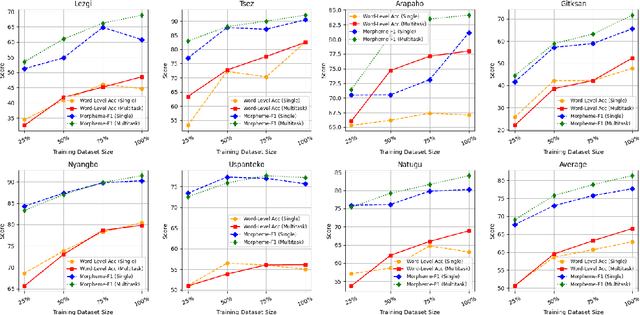
We introduce a transformer-based morpheme segmentation system that augments a low-resource training signal through multitask learning and LLM-generated synthetic data. Our framework jointly predicts morphological segments and glosses from orthographic input, leveraging shared linguistic representations obtained through a common documentary process to enhance model generalization. To further address data scarcity, we integrate synthetic training data generated by large language models (LLMs) using in-context learning. Experimental results on the SIGMORPHON 2023 dataset show that our approach significantly improves word-level segmentation accuracy and morpheme-level F1-score across multiple low-resource languages.
View paper on