Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Convolutional Network for Swahili News Classification
Paper and Code
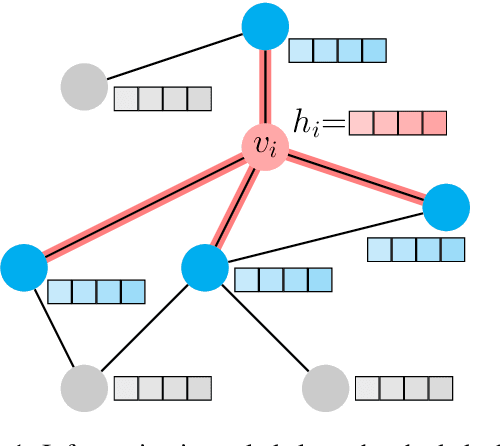
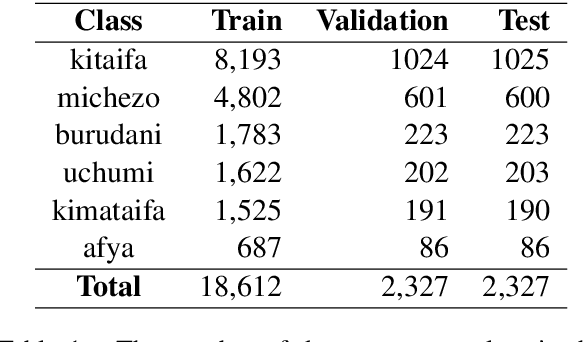
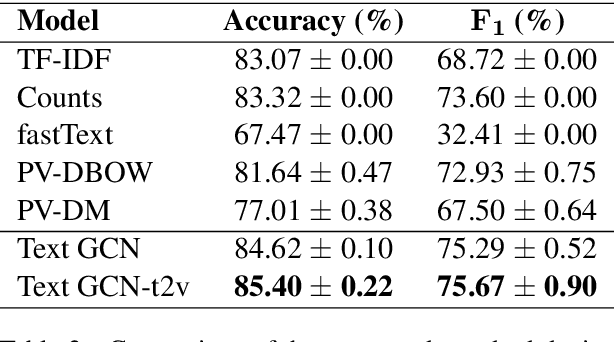
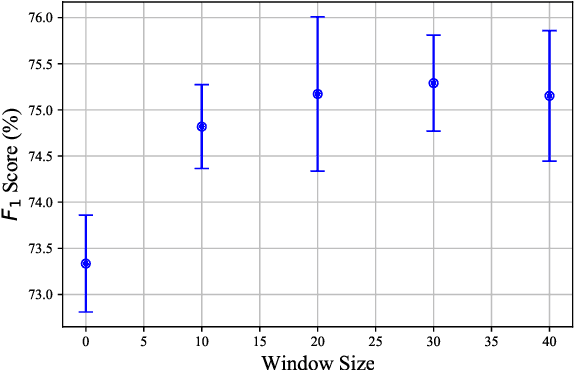
This work empirically demonstrates the ability of Text Graph Convolutional Network (Text GCN) to outperform traditional natural language processing benchmarks for the task of semi-supervised Swahili news classification. In particular, we focus our experimentation on the sparsely-labelled semi-supervised context which is representative of the practical constraints facing low-resourced African languages. We follow up on this result by introducing a variant of the Text GCN model which utilises a bag of words embedding rather than a naive one-hot encoding to reduce the memory footprint of Text GCN whilst demonstrating similar predictive performance.
* 8 pages, accepted at EACL AfricaNLP 2021
View paper on