 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Graph Generation via Pre-trained Language Models: An Empirical Study with Contrastive Learning
Paper and Code
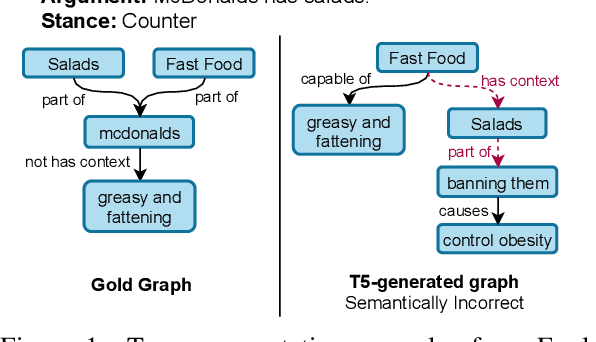
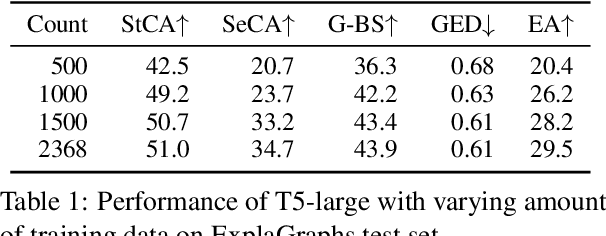
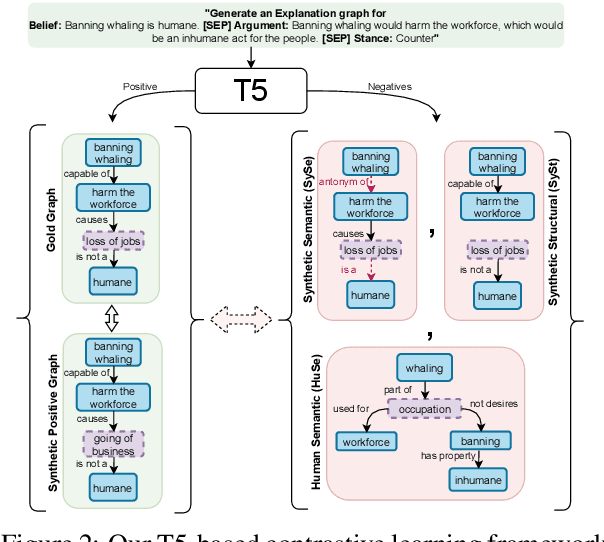
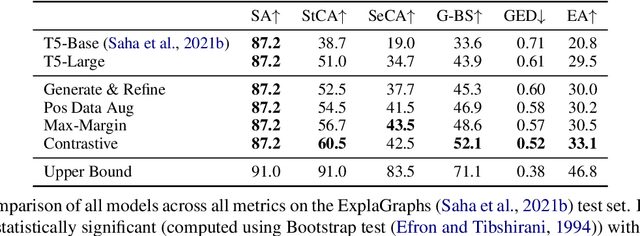
Pre-trained sequence-to-sequence language models have led to widespread success in many natural language generation tasks. However, there has been relatively less work on analyzing their ability to generate structured outputs such as graphs. Unlike natural language, graphs have distinct structural and semantic properties in the context of a downstream NLP task, e.g., generating a graph that is connected and acyclic can be attributed to its structural constraints, while the semantics of a graph can refer to how meaningfully an edge represents the relation between two node concepts. In this work, we study pre-trained language models that generate explanation graphs in an end-to-end manner and analyze their ability to learn the structural constraints and semantics of such graphs. We first show that with limited supervision, pre-trained language models often generate graphs that either violate these constraints or are semantically incoherent. Since curating large amount of human-annotated graphs is expensive and tedious, we propose simple yet effective ways of graph perturbations via node and edge edit operations that lead to structurally and semantically positive and negative graphs. Next, we leverage these graphs in different contrastive learning models with Max-Margin and InfoNCE losses. Our methods lead to significant improvements in both structural and semantic accuracy of explanation graphs and also generalize to other similar graph generation tasks. Lastly, we show that human errors are the best negatives for contrastive learning and also that automatically generating more such human-like negative graphs can lead to further improvements. Our code and models are publicly available at https://github.com/swarnaHub/ExplagraphGen