Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEDPUL: Method for Positive-Unlabeled Learning based on Density Estimation
Paper and Code
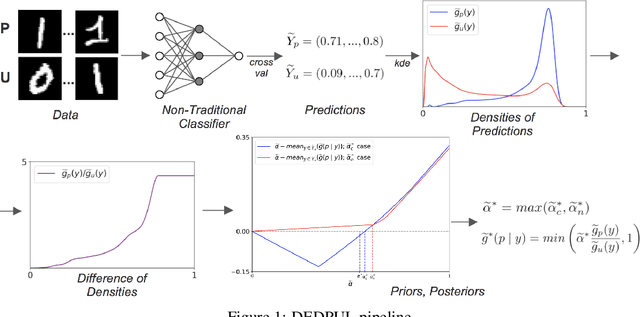
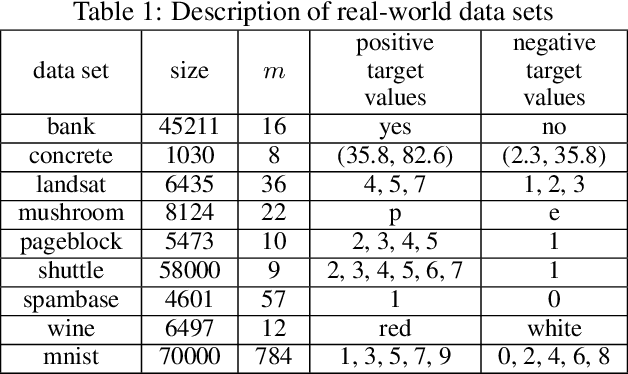
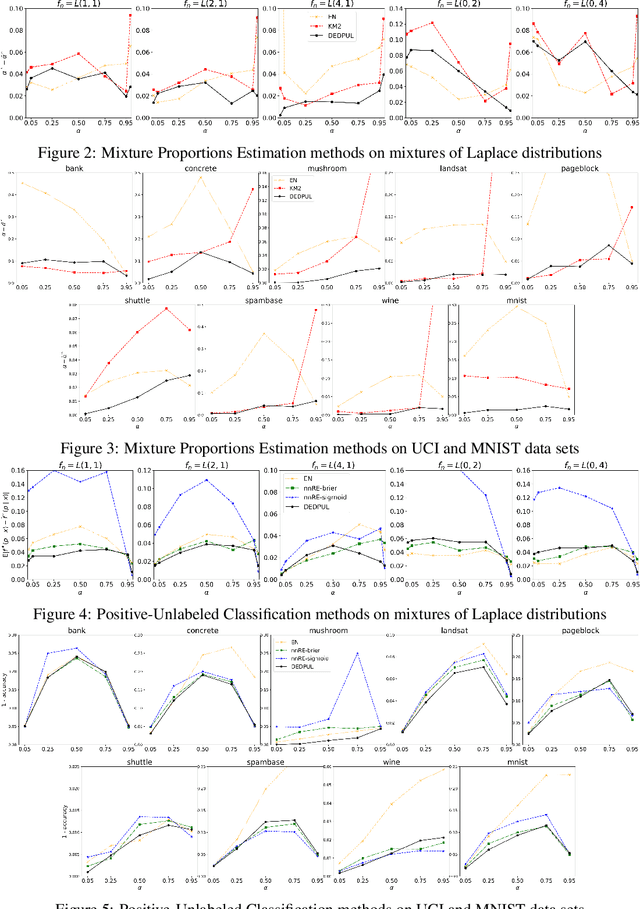
Positive-Unlabeled Classification is an analog of binary classification for the case when the Negative (N) sample in the training set is contaminated with latent instances of the Positive (P) class and hence is Unlabeled (U). We develop DEDPUL, a novel method that simultaneously solves two problems concerning U: estimates the proportions of the mixing components (P and N) in U and classifies U. We conduct experiments on synthetic and real-world data and show that DEDPUL outperforms current state-of-the-art methods for both problems. We suggest an automatic procedure for the objective choice of DEDPUL hyperparameters. Additionally, we improve two methods from the literature.
* Implementation of DEDPUL and experimental data may be found at
https://github.com/dimonenka/DEDPUL
View paper on