Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus Statistics Meet the Noun Compound: Some Empirical Results
Sep 10, 1996

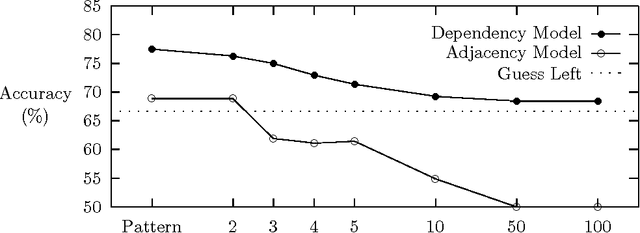
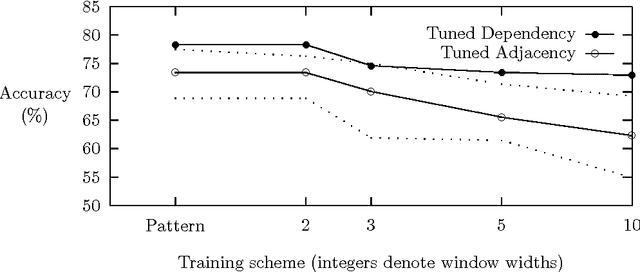
A variety of statistical methods for noun compound analysis are implemented and compared. The results support two main conclusions. First, the use of conceptual association not only enables a broad coverage, but also improves the accuracy. Second, an analysis model based on dependency grammar is substantially more accurate than one based on deepest constituents, even though the latter is more prevalent in the literature.
* Proceedings of the 33rd Annual Meeting of the Association for
Computational Linguistics, Boston, MA., 1995 pp47-54 * 8 pages, 5 figures, uses modified version of aclap.sty, replaced
because old version failed to TeX properly
View paper on