 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorefDRE: Document-level Relation Extraction with coreference resolution
Paper and Code
Feb 22, 2022

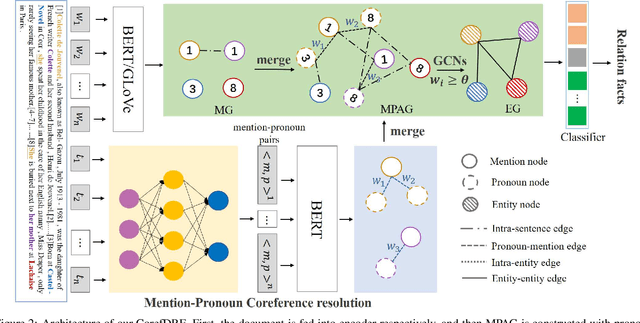
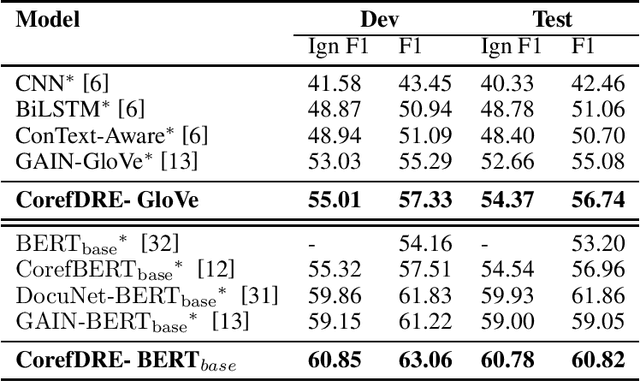
Document-level relation extraction is to extract relation facts from a document consisting of multiple sentences, in which pronoun crossed sentences are a ubiquitous phenomenon against a single sentence. However, most of the previous works focus more on mentions coreference resolution except for pronouns, and rarely pay attention to mention-pronoun coreference and capturing the relations. To represent multi-sentence features by pronouns, we imitate the reading process of humans by leveraging coreference information when dynamically constructing a heterogeneous graph to enhance semantic information. Since the pronoun is notoriously ambiguous in the graph, a mention-pronoun coreference resolution is introduced to calculate the affinity between pronouns and corresponding mentions, and the noise suppression mechanism is proposed to reduce the noise caused by pronouns. Experiments on the public dataset, DocRED, DialogRE and MPDD, show that Coref-aware Doc-level Relation Extraction based on Graph Inference Network outperforms the state-of-the-art.