Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-switched Language Models Using Dual RNNs and Same-Source Pretraining
Paper and Code
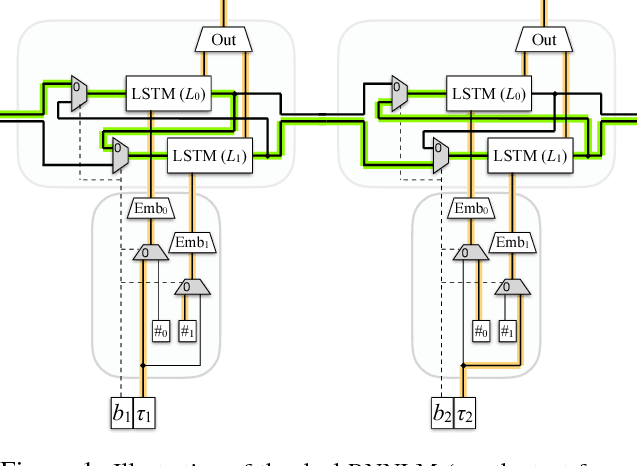
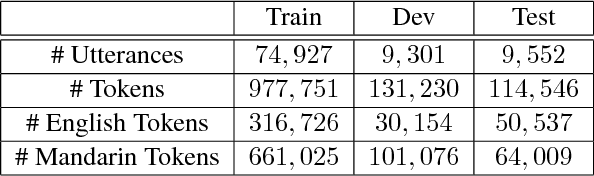
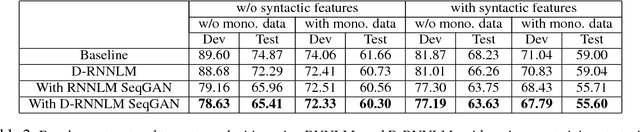
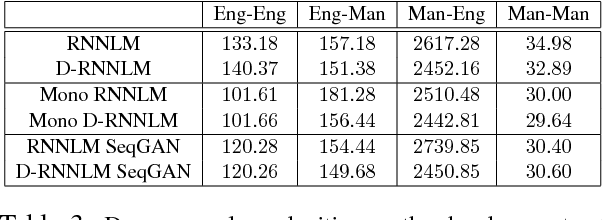
This work focuses on building language models (LMs) for code-switched text. We propose two techniques that significantly improve these LMs: 1) A novel recurrent neural network unit with dual components that focus on each language in the code-switched text separately 2) Pretraining the LM using synthetic text from a generative model estimated using the training data. We demonstrate the effectiveness of our proposed techniques by reporting perplexities on a Mandarin-English task and derive significant reductions in perplexity.
* Accepted at EMNLP 2018
View paper on