 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEST-STD2.0: Balanced and Efficient Speech Tokenizer for Spoken Term Detection
Paper and Code
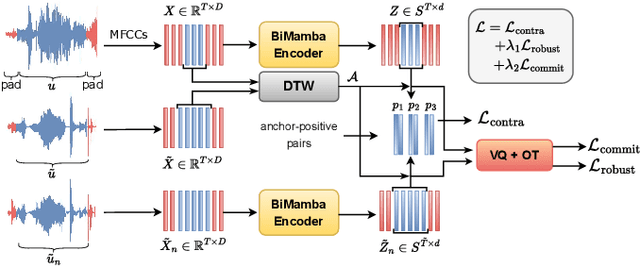
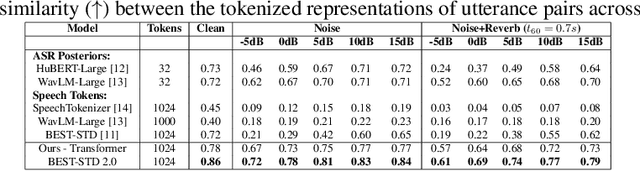
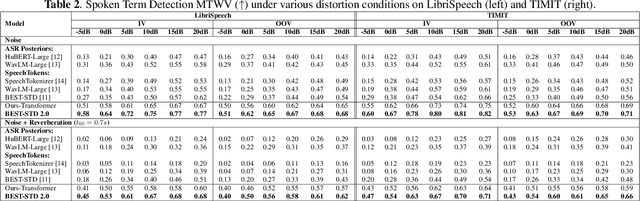
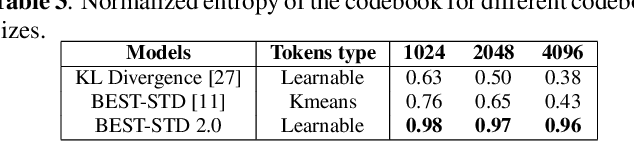
Fast and accurate spoken content retrieval is vital for applications such as voice search. Query-by-Example Spoken Term Detection (STD) involves retrieving matching segments from an audio database given a spoken query. Token-based STD systems, which use discrete speech representations, enable efficient search but struggle with robustness to noise and reverberation, and with inefficient token utilization. We address these challenges by proposing a noise and reverberation-augmented training strategy to improve tokenizer robustness. In addition, we introduce optimal transport-based regularization to ensure balanced token usage and enhance token efficiency. To further speed up retrieval, we adopt a TF-IDF-based search mechanism. Empirical evaluations demonstrate that the proposed method outperforms STD baselines across various distortion levels while maintaining high search efficiency.