Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA statistical model for word discovery in child directed speech
Paper and Code
Oct 13, 1999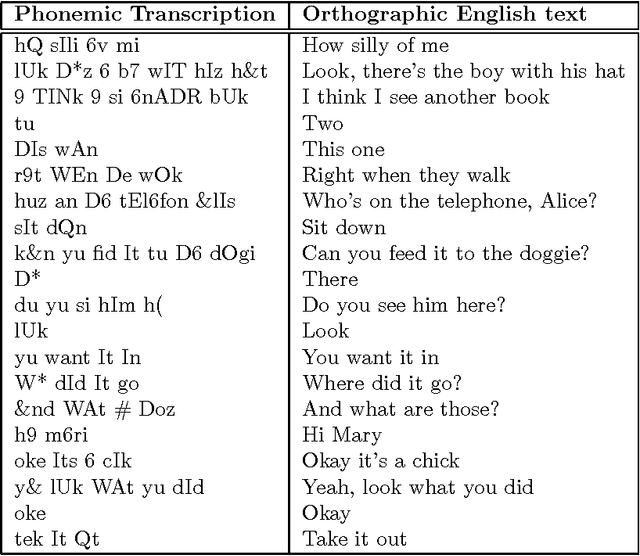


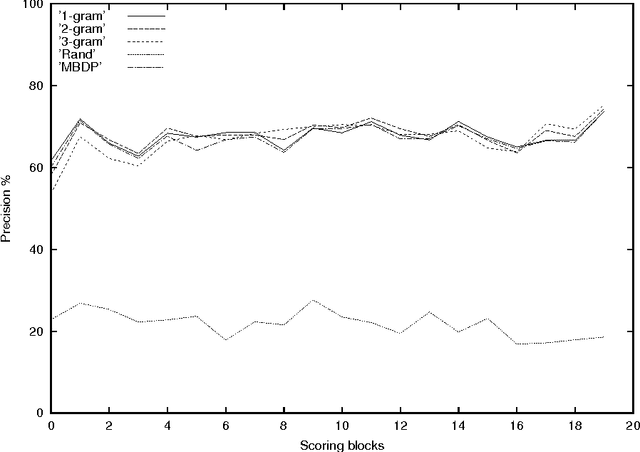
A statistical model for segmentation and word discovery in child directed speech is presented. An incremental unsupervised learning algorithm to infer word boundaries based on this model is described and results of empirical tests showing that the algorithm is competitive with other models that have been used for similar tasks are also presented.
* 48 pgs, 10 figs
View paper on