 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Grammar Induction Using Training Data with Limited Constituent Information
Paper and Code
May 02, 1999
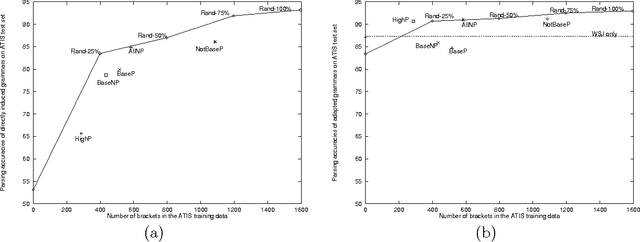
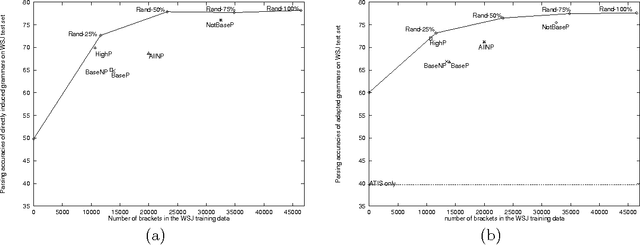
Corpus-based grammar induction generally relies on hand-parsed training data to learn the structure of the language. Unfortunately, the cost of building large annotated corpora is prohibitively expensive. This work aims to improve the induction strategy when there are few labels in the training data. We show that the most informative linguistic constituents are the higher nodes in the parse trees, typically denoting complex noun phrases and sentential clauses. They account for only 20% of all constituents. For inducing grammars from sparsely labeled training data (e.g., only higher-level constituent labels), we propose an adaptation strategy, which produces grammars that parse almost as well as grammars induced from fully labeled corpora. Our results suggest that for a partial parser to replace human annotators, it must be able to automatically extract higher-level constituents rather than base noun phrases.