 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Identification of Subjects for Textual Documents in Digital Libraries
Paper and Code
Feb 01, 1999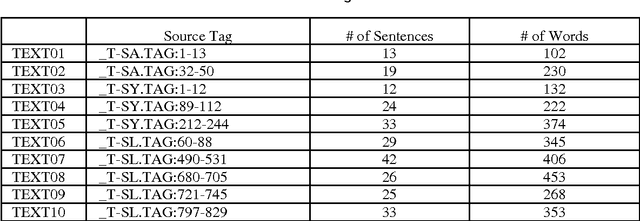

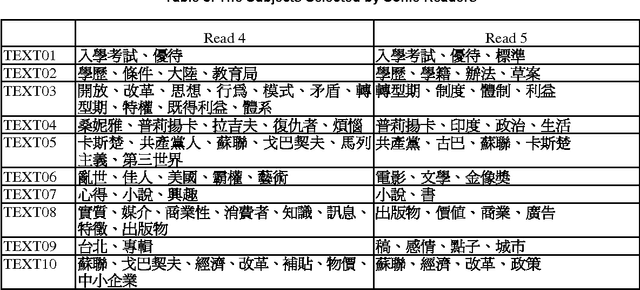
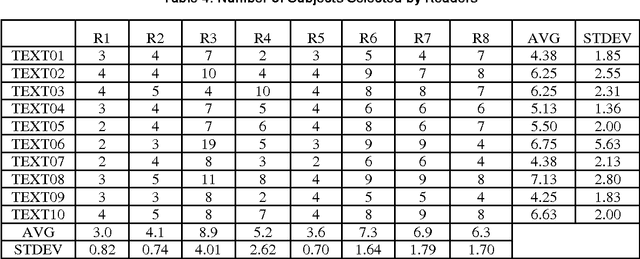
The amount of electronic documents in the Internet grows very quickly. How to effectively identify subjects for documents becomes an important issue. In past, the researches focus on the behavior of nouns in documents. Although subjects are composed of nouns, the constituents that determine which nouns are subjects are not only nouns. Based on the assumption that texts are well-organized and event-driven, nouns and verbs together contribute the process of subject identification. This paper considers four factors: 1) word importance, 2) word frequency, 3) word co-occurrence, and 4) word distance and proposes a model to identify subjects for textual documents. The preliminary experiments show that the performance of the proposed model is close to that of human beings.