 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Matching and Discourse Processing in Information Extraction from Japanese Text
Paper and Code
Aug 01, 1994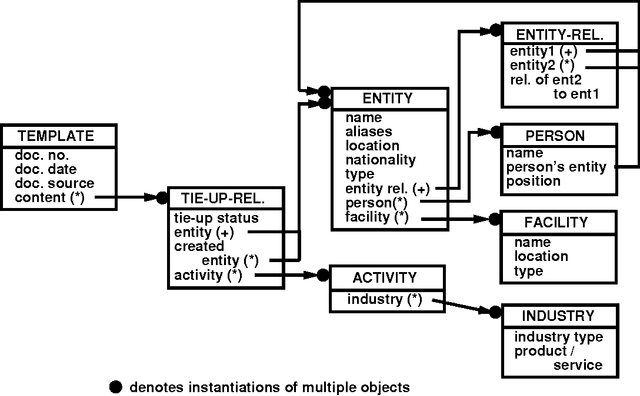
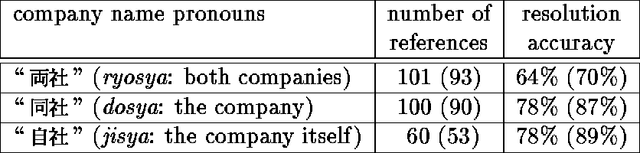
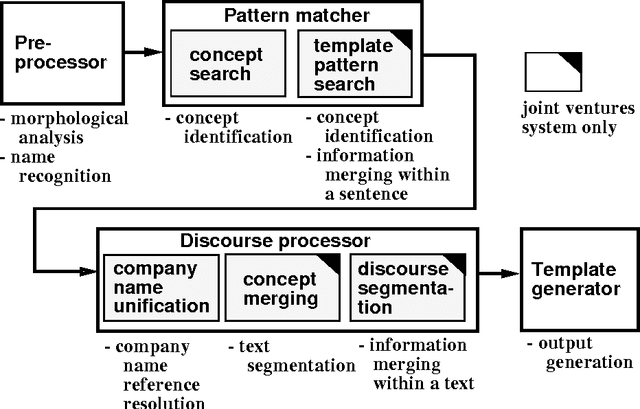
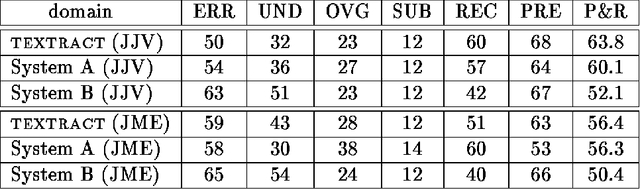
Information extraction is the task of automatically picking up information of interest from an unconstrained text. Information of interest is usually extracted in two steps. First, sentence level processing locates relevant pieces of information scattered throughout the text; second, discourse processing merges coreferential information to generate the output. In the first step, pieces of information are locally identified without recognizing any relationships among them. A key word search or simple pattern search can achieve this purpose. The second step requires deeper knowledge in order to understand relationships among separately identified pieces of information. Previous information extraction systems focused on the first step, partly because they were not required to link up each piece of information with other pieces. To link the extracted pieces of information and map them onto a structured output format, complex discourse processing is essential. This paper reports on a Japanese information extraction system that merges information using a pattern matcher and discourse processor. Evaluation results show a high level of system performance which approaches human performance.