 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tool set for the quick and efficient exploration of large document collections
Paper and Code
Sep 12, 2006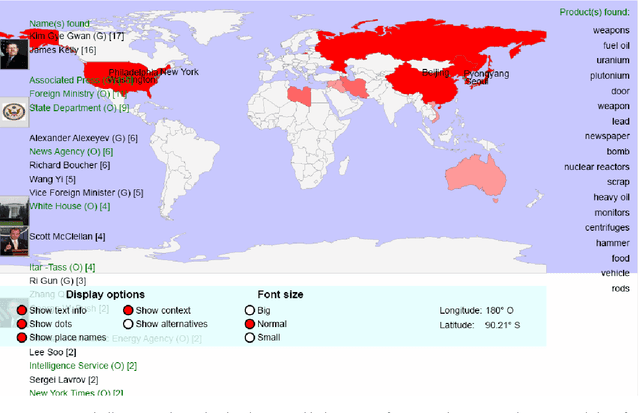

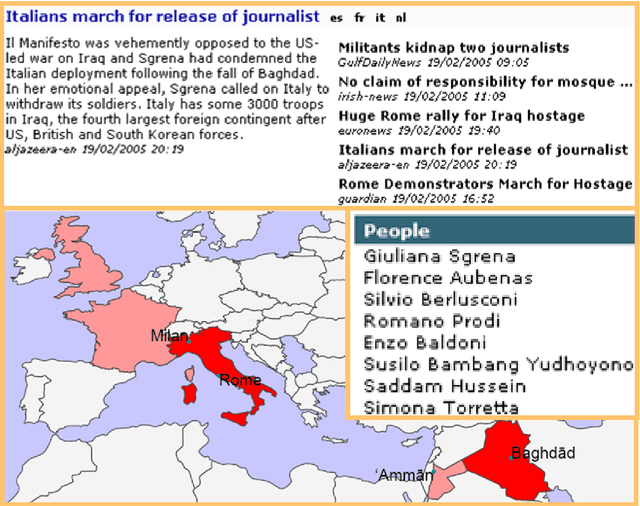

We are presenting a set of multilingual text analysis tools that can help analysts in any field to explore large document collections quickly in order to determine whether the documents contain information of interest, and to find the relevant text passages. The automatic tool, which currently exists as a fully functional prototype, is expected to be particularly useful when users repeatedly have to sieve through large collections of documents such as those downloaded automatically from the internet. The proposed system takes a whole document collection as input. It first carries out some automatic analysis tasks (named entity recognition, geo-coding, clustering, term extraction), annotates the texts with the generated meta-information and stores the meta-information in a database. The system then generates a zoomable and hyperlinked geographic map enhanced with information on entities and terms found. When the system is used on a regular basis, it builds up a historical database that contains information on which names have been mentioned together with which other names or places, and users can query this database to retrieve information extracted in the past.