Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthoring case based training by document data extraction
Paper and Code
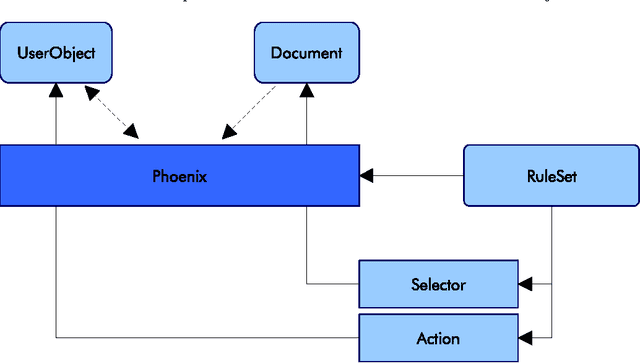
In this paper, we propose an scalable approach to modeling based upon word processing documents, and we describe the tool Phoenix providing the technical infrastructure. For our training environment d3web.Train, we developed a tool to extract case knowledge from existing documents, usually dismissal records, extending Phoenix to d3web.CaseImporter. Independent authors used this tool to develop training systems, observing a significant decrease of time for setteling-in and a decrease of time necessary for developing a case.
* 11 pages, 10th ChEM Workshop, 2005; technical article
View paper on