 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine and Word Matching in Old Documents
Paper and Code
Dec 17, 2004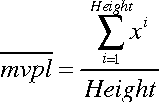


This paper is concerned with the problem of establishing an index based on word matching. It is assumed that the book was digitised as better as possible and some pre-processing techniques were already applied as line orientation correction and some noise removal. However two main factor are responsible for being not possible to apply ordinary optical character recognition techniques (OCR): the presence of antique fonts and the degraded state of many characters due to unrecoverable original time degradation. In this paper we make a short introduction to word segmentation that involves finding the lines that characterise a word. After we discuss different approaches for word matching and how they can be combined to obtain an ordered list for candidate words for the matching. This discussion will be illustrated by examples.