Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatching the Drift: Probabilistic Content Models, with Applications to Generation and Summarization
Paper and Code
May 12, 2004
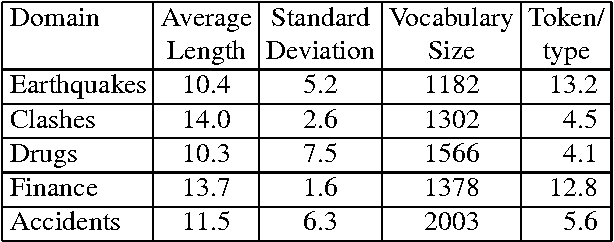
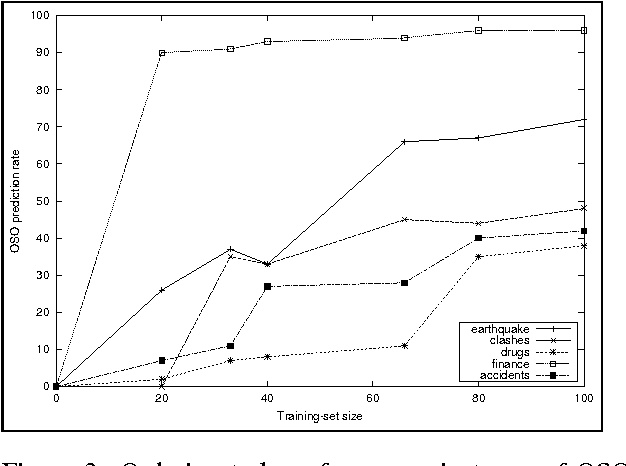
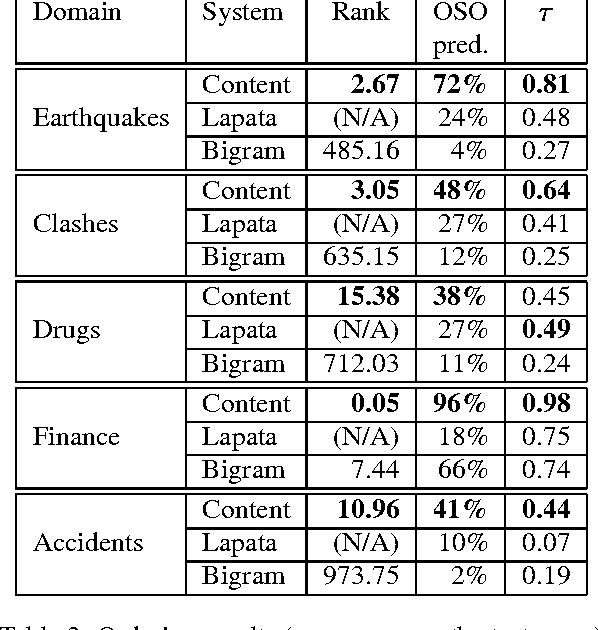
We consider the problem of modeling the content structure of texts within a specific domain, in terms of the topics the texts address and the order in which these topics appear. We first present an effective knowledge-lean method for learning content models from un-annotated documents, utilizing a novel adaptation of algorithms for Hidden Markov Models. We then apply our method to two complementary tasks: information ordering and extractive summarization. Our experiments show that incorporating content models in these applications yields substantial improvement over previously-proposed methods.
* HLT-NAACL 2004: Proceedings of the Main Conference, pp. 113--120 * Best paper award
View paper on