Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree New Methods for Evaluating Reference Resolution
Paper and Code
Aug 21, 2002
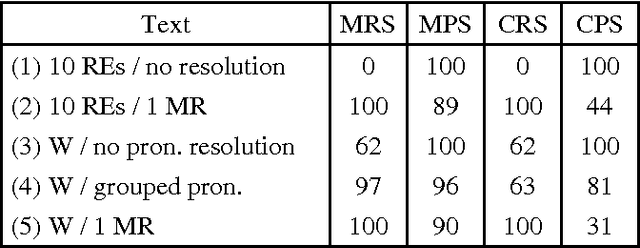
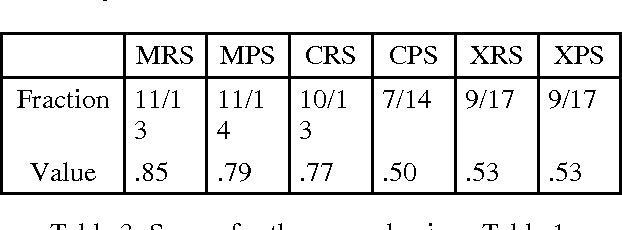
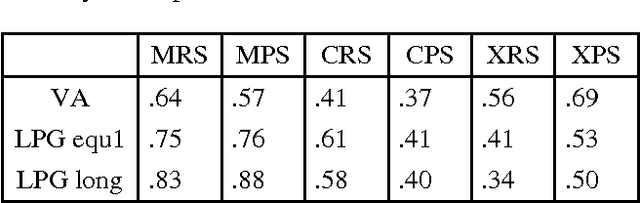
Reference resolution on extended texts (several thousand references) cannot be evaluated manually. An evaluation algorithm has been proposed for the MUC tests, using equivalence classes for the coreference relation. However, we show here that this algorithm is too indulgent, yielding good scores even for poor resolution strategies. We elaborate on the same formalism to propose two new evaluation algorithms, comparing them first with the MUC algorithm and giving then results on a variety of examples. A third algorithm using only distributional comparison of equivalence classes is finally described; it assesses the relative importance of the recall vs. precision errors.
* Proceedings of the LREC'98 Workshop on Linguistic Coreference,
Madrid, Spain, 1998 * 7 pages
View paper on