 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining All Non-Derivable Frequent Itemsets
Paper and Code
Jun 03, 2002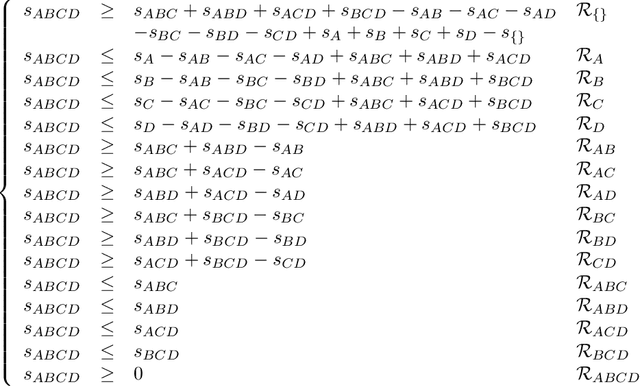
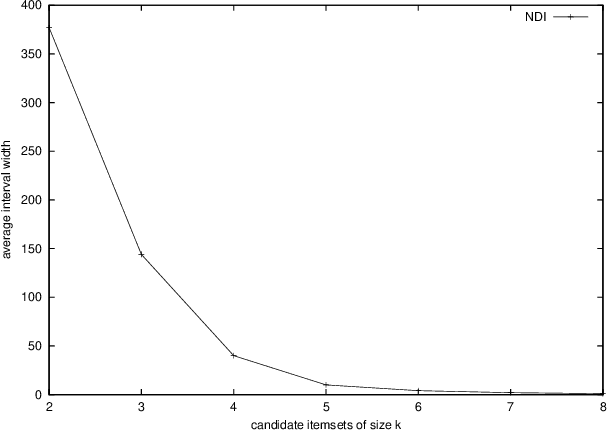
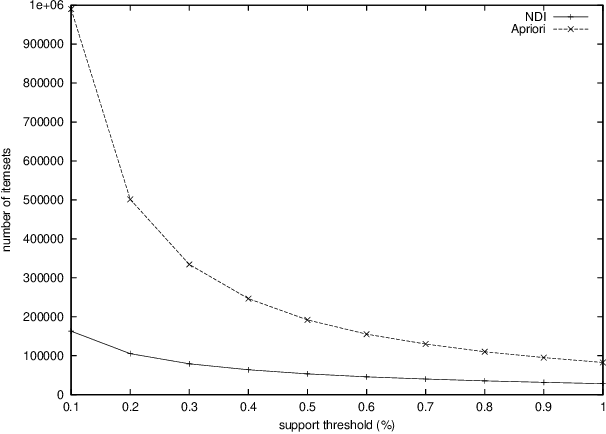
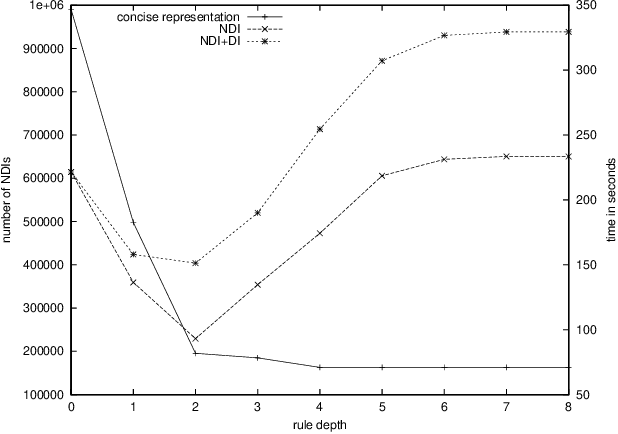
Recent studies on frequent itemset mining algorithms resulted in significant performance improvements. However, if the minimal support threshold is set too low, or the data is highly correlated, the number of frequent itemsets itself can be prohibitively large. To overcome this problem, recently several proposals have been made to construct a concise representation of the frequent itemsets, instead of mining all frequent itemsets. The main goal of this paper is to identify redundancies in the set of all frequent itemsets and to exploit these redundancies in order to reduce the result of a mining operation. We present deduction rules to derive tight bounds on the support of candidate itemsets. We show how the deduction rules allow for constructing a minimal representation for all frequent itemsets. We also present connections between our proposal and recent proposals for concise representations and we give the results of experiments on real-life datasets that show the effectiveness of the deduction rules. In fact, the experiments even show that in many cases, first mining the concise representation, and then creating the frequent itemsets from this representation outperforms existing frequent set mining algorithms.