 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Normalization of Speech From Different Channels and Speakers
Paper and Code
Apr 02, 2002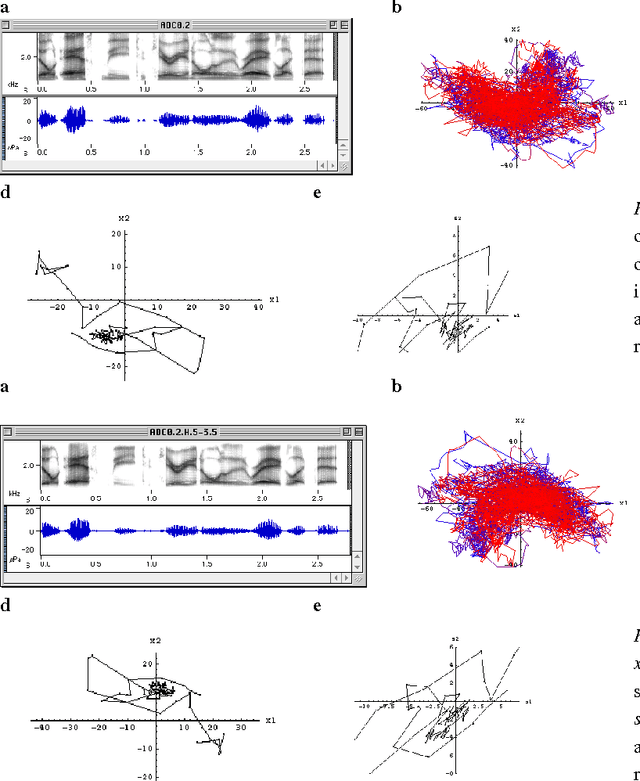
This paper describes representations of time-dependent signals that are invariant under any invertible time-independent transformation of the signal time series. Such a representation is created by rescaling the signal in a non-linear dynamic manner that is determined by recently encountered signal levels. This technique may make it possible to normalize signals that are related by channel-dependent and speaker-dependent transformations, without having to characterize the form of the signal transformations, which remain unknown. The technique is illustrated by applying it to the time-dependent spectra of speech that has been filtered to simulate the effects of different channels. The experimental results show that the rescaled speech representations are largely normalized (i.e., channel-independent), despite the channel-dependence of the raw (unrescaled) speech.