Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA procedure for unsupervised lexicon learning
Paper and Code
Nov 30, 2001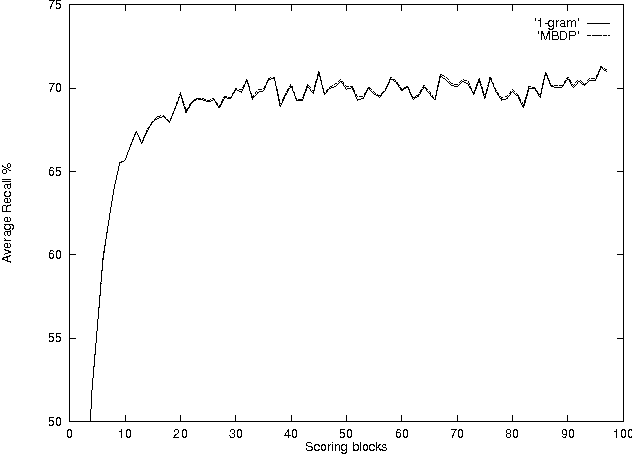
We describe an incremental unsupervised procedure to learn words from transcribed continuous speech. The algorithm is based on a conservative and traditional statistical model, and results of empirical tests show that it is competitive with other algorithms that have been proposed recently for this task.
* Proceedings of the eighteenth international conference on machine
learning, ICML-01, pp.569--576, 2001 * Expanded version of this paper appears in Computational Linguistics
27(3)
View paper on