 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-of-Speech Tagging with Two Sequential Transducers
Paper and Code
Oct 11, 2001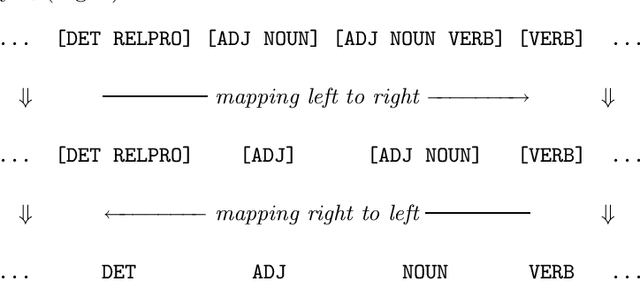
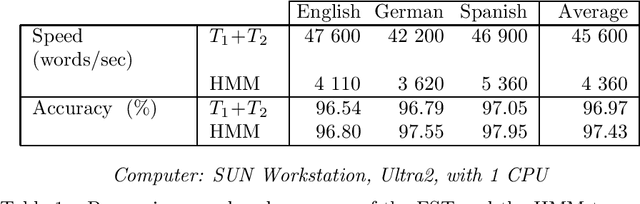

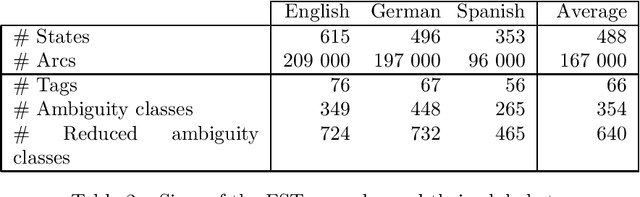
We present a method of constructing and using a cascade consisting of a left- and a right-sequential finite-state transducer (FST), T1 and T2, for part-of-speech (POS) disambiguation. Compared to an HMM, this FST cascade has the advantage of significantly higher processing speed, but at the cost of slightly lower accuracy. Applications such as Information Retrieval, where the speed can be more important than accuracy, could benefit from this approach. In the process of tagging, we first assign every word a unique ambiguity class c_i that can be looked up in a lexicon encoded by a sequential FST. Every c_i is denoted by a single symbol, e.g. [ADJ_NOUN], although it represents a set of alternative tags that a given word can occur with. The sequence of the c_i of all words of one sentence is the input to our FST cascade. It is mapped by T1, from left to right, to a sequence of reduced ambiguity classes r_i. Every r_i is denoted by a single symbol, although it represents a set of alternative tags. Intuitively, T1 eliminates the less likely tags from c_i, thus creating r_i. Finally, T2 maps the sequence of r_i, from right to left, to a sequence of single POS tags t_i. Intuitively, T2 selects the most likely t_i from every r_i. The probabilities of all t_i, r_i, and c_i are used only at compile time, not at run time. They do not (directly) occur in the FSTs, but are "implicitly contained" in their structure.