 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Phonemic Annotation of Corpora
Paper and Code
Aug 18, 2000
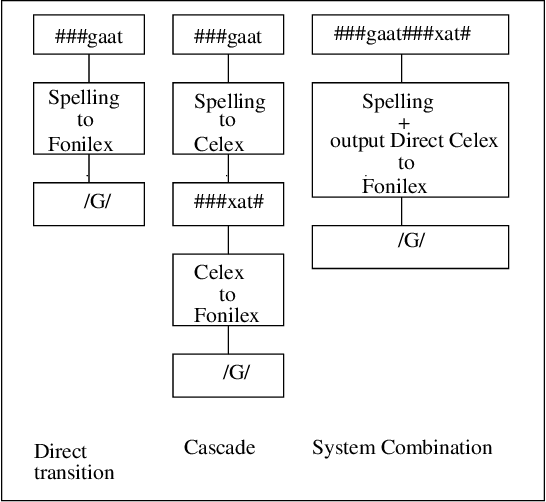

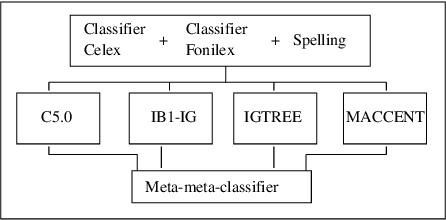
We apply rule induction, classifier combination and meta-learning (stacked classifiers) to the problem of bootstrapping high accuracy automatic annotation of corpora with pronunciation information. The task we address in this paper consists of generating phonemic representations reflecting the Flemish and Dutch pronunciations of a word on the basis of its orthographic representation (which in turn is based on the actual speech recordings). We compare several possible approaches to achieve the text-to-pronunciation mapping task: memory-based learning, transformation-based learning, rule induction, maximum entropy modeling, combination of classifiers in stacked learning, and stacking of meta-learners. We are interested both in optimal accuracy and in obtaining insight into the linguistic regularities involved. As far as accuracy is concerned, an already high accuracy level (93% for Celex and 86% for Fonilex at word level) for single classifiers is boosted significantly with additional error reductions of 31% and 38% respectively using combination of classifiers, and a further 5% using combination of meta-learners, bringing overall word level accuracy to 96% for the Dutch variant and 92% for the Flemish variant. We also show that the application of machine learning methods indeed leads to increased insight into the linguistic regularities determining the variation between the two pronunciation variants studied.