 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-Based Approaches to Natural Language Processing
Paper and Code
Aug 19, 1997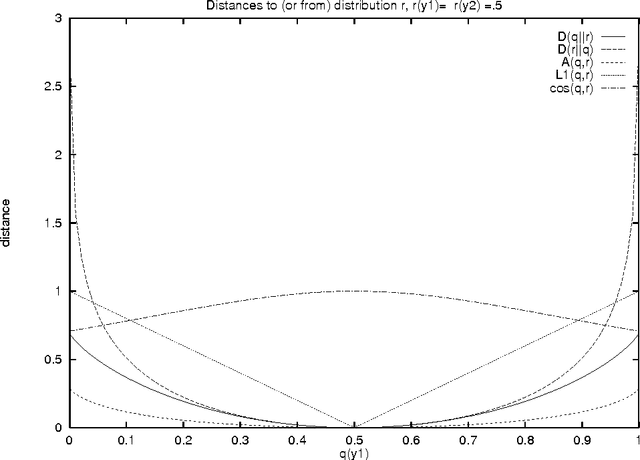

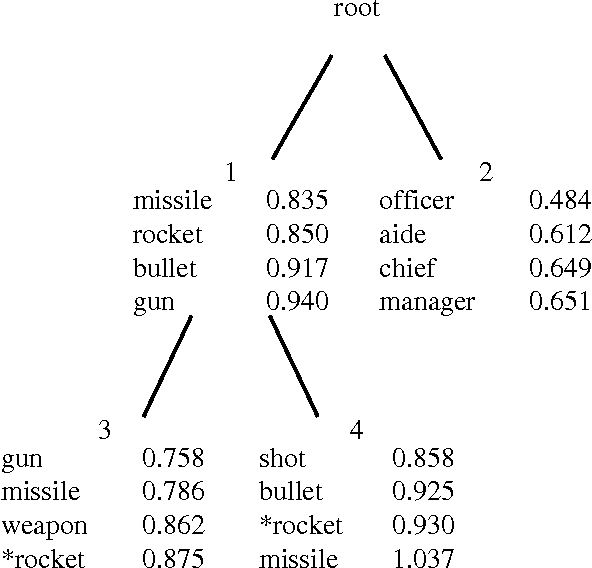
This thesis presents two similarity-based approaches to sparse data problems. The first approach is to build soft, hierarchical clusters: soft, because each event belongs to each cluster with some probability; hierarchical, because cluster centroids are iteratively split to model finer distinctions. Our second approach is a nearest-neighbor approach: instead of calculating a centroid for each class, as in the hierarchical clustering approach, we in essence build a cluster around each word. We compare several such nearest-neighbor approaches on a word sense disambiguation task and find that as a whole, their performance is far superior to that of standard methods. In another set of experiments, we show that using estimation techniques based on the nearest-neighbor model enables us to achieve perplexity reductions of more than 20 percent over standard techniques in the prediction of low-frequency events, and statistically significant speech recognition error-rate reduction.