 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Statistical Parsing of Noun Phrases for Document Indexing
Paper and Code
Feb 12, 1997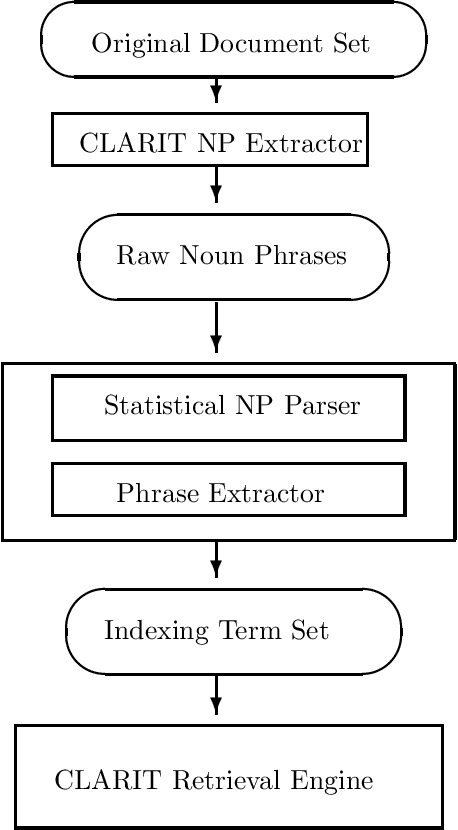
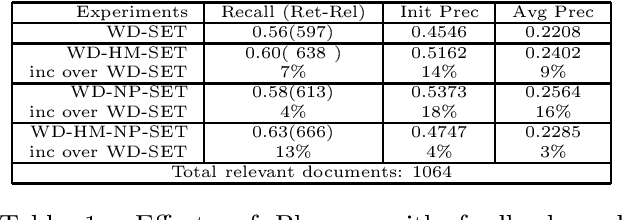
Information Retrieval (IR) is an important application area of Natural Language Processing (NLP) where one encounters the genuine challenge of processing large quantities of unrestricted natural language text. While much effort has been made to apply NLP techniques to IR, very few NLP techniques have been evaluated on a document collection larger than several megabytes. Many NLP techniques are simply not efficient enough, and not robust enough, to handle a large amount of text. This paper proposes a new probabilistic model for noun phrase parsing, and reports on the application of such a parsing technique to enhance document indexing. The effectiveness of using syntactic phrases provided by the parser to supplement single words for indexing is evaluated with a 250 megabytes document collection. The experiment's results show that supplementing single words with syntactic phrases for indexing consistently and significantly improves retrieval performance.