Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Model of Compound Nouns
Paper and Code
Sep 06, 1994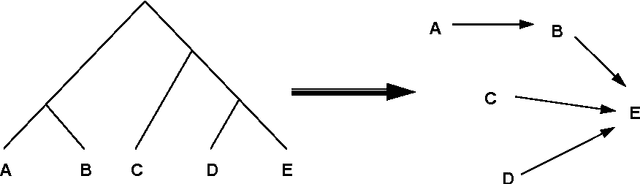
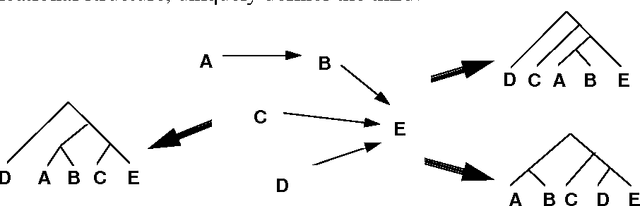
Compound nouns such as example noun compound are becoming more common in natural language and pose a number of difficult problems for NLP systems, notably increasing the complexity of parsing. In this paper we develop a probabilistic model for syntactically analysing such compounds. The model predicts compound noun structures based on knowledge of affinities between nouns, which can be acquired from a corpus. Problems inherent in this corpus-based approach are addressed: data sparseness is overcome by the use of semantically motivated word classes and sense ambiguity is explicitly handled in the model. An implementation based on this model is described in Lauer (1994) and correctly parses 77% of the test set.
* 7th Australian Joint Conference on AI, 1994 * 9 pages, uuencoded compressed postscript, please ignore any undefined
command error at end
View paper on