Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering From Parser Failures: A Hybrid Statistical/Symbolic Approach
Paper and Code
Jul 28, 1994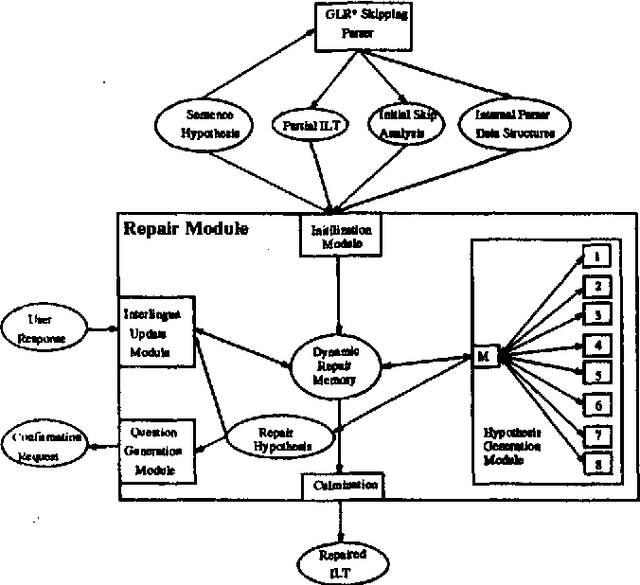
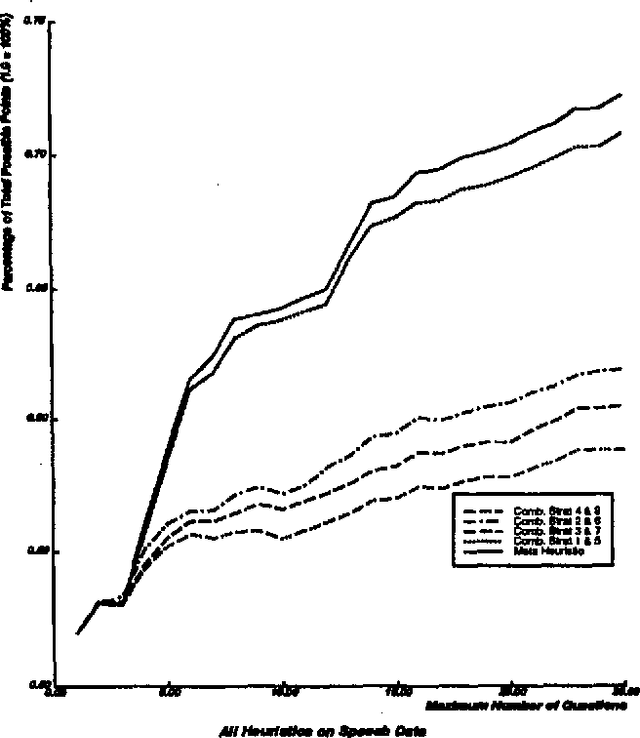
We describe an implementation of a hybrid statistical/symbolic approach to repairing parser failures in a speech-to-speech translation system. We describe a module which takes as input a fragmented parse and returns a repaired meaning representation. It negotiates with the speaker about what the complete meaning of the utterance is by generating hypotheses about how to fit the fragments of the partial parse together into a coherent meaning representation. By drawing upon both statistical and symbolic information, it constrains its repair hypotheses to those which are both likely and meaningful. Because it updates its statistical model during use, it improves its performance over time.
View paper on