Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Discourse Analysis of Parallel Texts
Paper and Code
Jul 26, 1994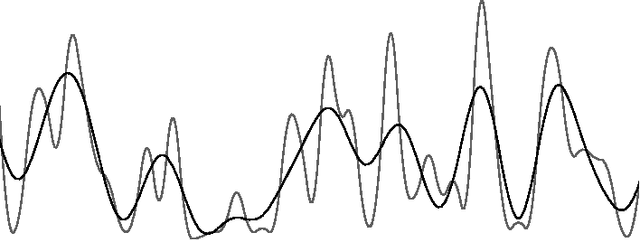
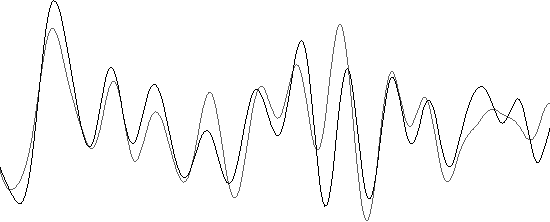
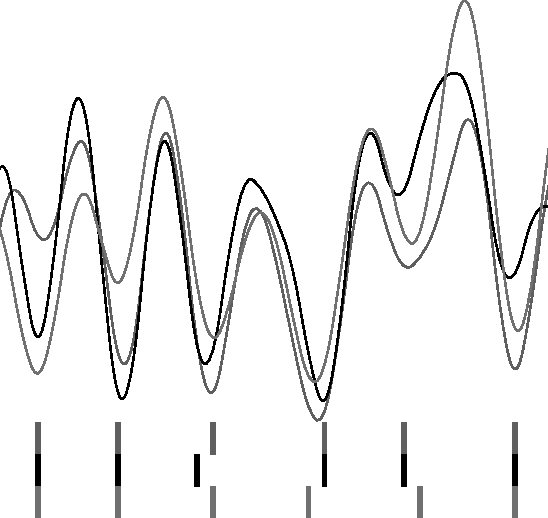
A quantitative representation of discourse structure can be computed by measuring lexical cohesion relations among adjacent blocks of text. These representations have been proposed to deal with sub-topic text segmentation. In a parallel corpus, similar representations can be derived for versions of a text in various languages. These can be used for parallel segmentation and as an alternative measure of text-translation similarity.
* 11 pages uuencoded compressed Postscript
View paper on