Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-vec: A New Approach for Aligning Parallel Texts
Paper and Code
Jul 25, 1994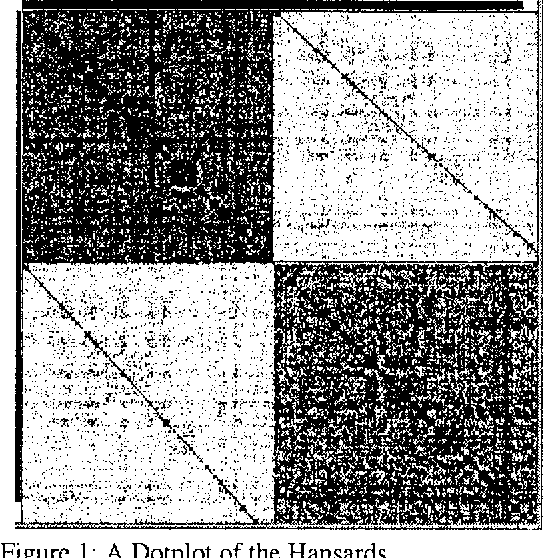
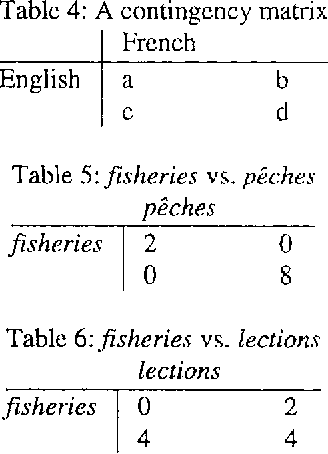
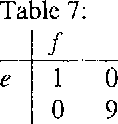
Various methods have been proposed for aligning texts in two or more languages such as the Canadian Parliamentary Debates(Hansards). Some of these methods generate a bilingual lexicon as a by-product. We present an alternative alignment strategy which we call K-vec, that starts by estimating the lexicon. For example, it discovers that the English word "fisheries" is similar to the French "pe^ches" by noting that the distribution of "fisheries" in the English text is similar to the distribution of "pe^ches" in the French. K-vec does not depend on sentence boundaries.
* 7 pages, uuencoded, compressed PostScript; Proc. COLING-94
View paper on