 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus-Driven Knowledge Acquisition for Discourse Analysis
Paper and Code
Jun 07, 1994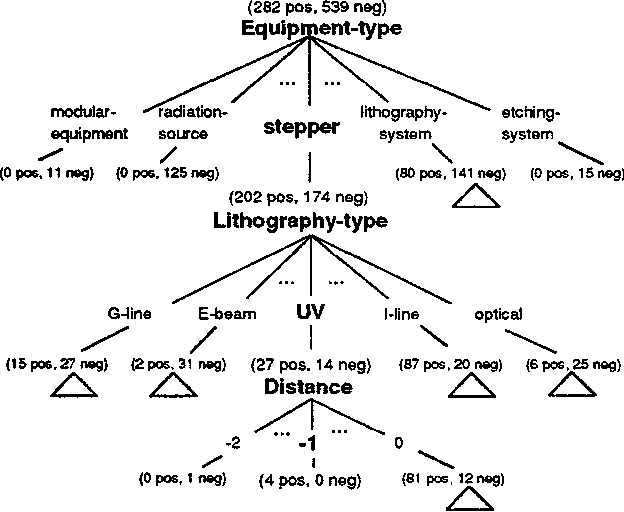


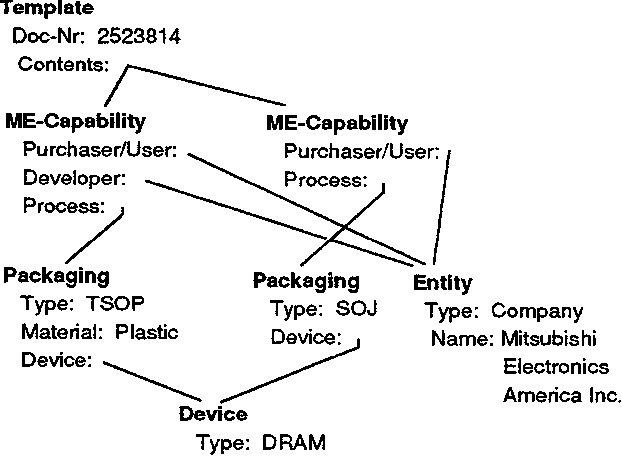
The availability of large on-line text corpora provides a natural and promising bridge between the worlds of natural language processing (NLP) and machine learning (ML). In recent years, the NLP community has been aggressively investigating statistical techniques to drive part-of-speech taggers, but application-specific text corpora can be used to drive knowledge acquisition at much higher levels as well. In this paper we will show how ML techniques can be used to support knowledge acquisition for information extraction systems. It is often very difficult to specify an explicit domain model for many information extraction applications, and it is always labor intensive to implement hand-coded heuristics for each new domain. We have discovered that it is nevertheless possible to use ML algorithms in order to capture knowledge that is only implicitly present in a representative text corpus. Our work addresses issues traditionally associated with discourse analysis and intersentential inference generation, and demonstrates the utility of ML algorithms at this higher level of language analysis. The benefits of our work address the portability and scalability of information extraction (IE) technologies. When hand-coded heuristics are used to manage discourse analysis in an information extraction system, months of programming effort are easily needed to port a successful IE system to a new domain. We will show how ML algorithms can reduce this