Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularity in a Connectionist Model of Morphology Acquisition
Paper and Code
May 30, 1994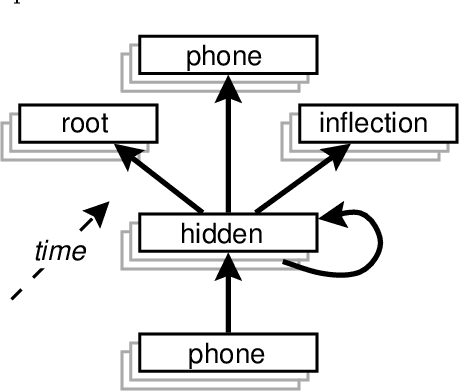
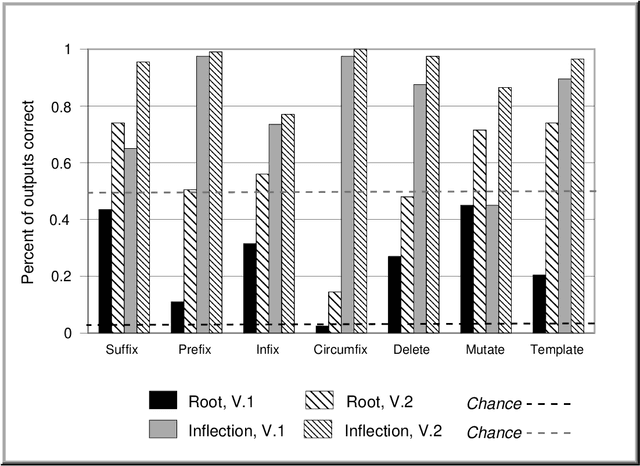
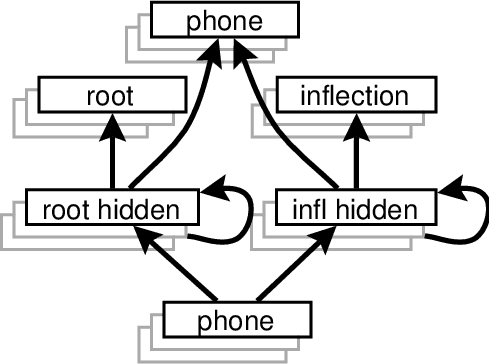
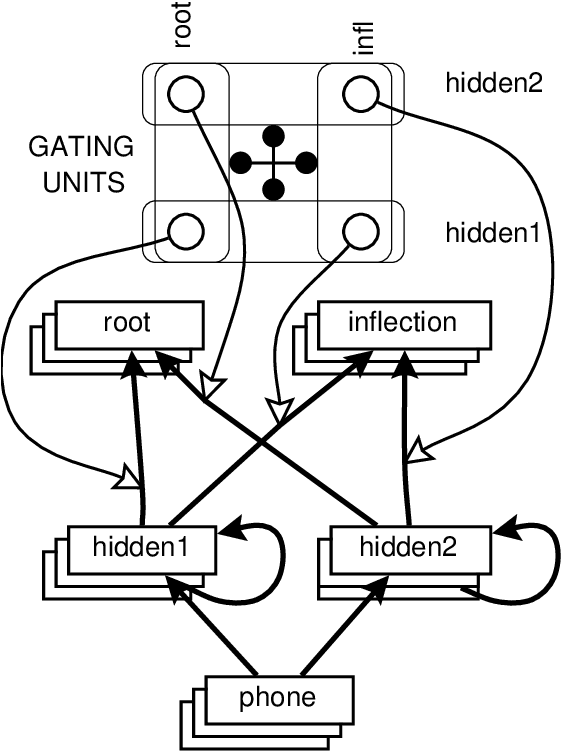
This paper describes a modular connectionist model of the acquisition of receptive inflectional morphology. The model takes inputs in the form of phones one at a time and outputs the associated roots and inflections. In its simplest version, the network consists of separate simple recurrent subnetworks for root and inflection identification; both networks take the phone sequence as inputs. It is shown that the performance of the two separate modular networks is superior to a single network responsible for both root and inflection identification. In a more elaborate version of the model, the network learns to use separate hidden-layer modules to solve the separate tasks of root and inflection identification.
* Proceedings of COLING 94 * 7 pages, uuencoded compressed Postscript file
View paper on