 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-first Model Merging for Hidden Markov Model Induction
Paper and Code
May 10, 1994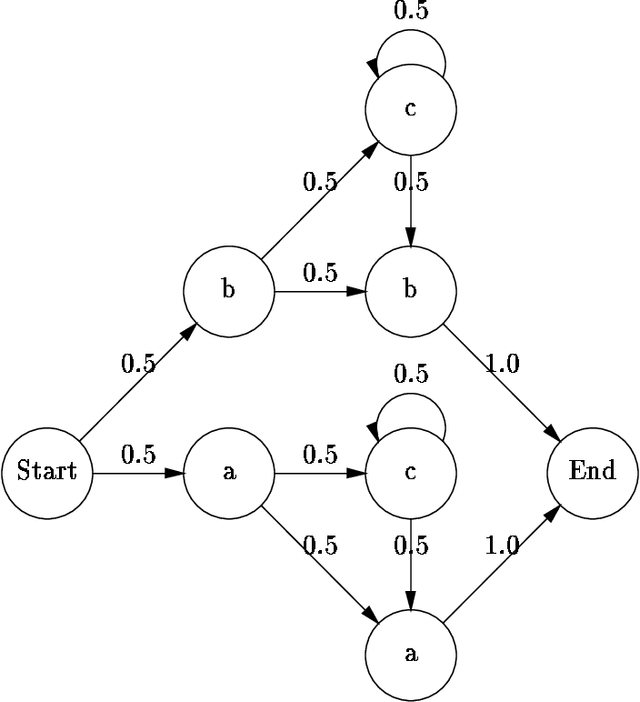
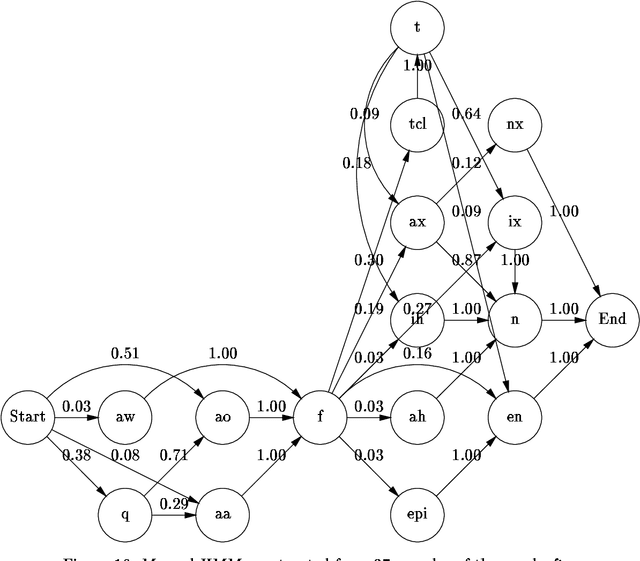
This report describes a new technique for inducing the structure of Hidden Markov Models from data which is based on the general `model merging' strategy (Omohundro 1992). The process begins with a maximum likelihood HMM that directly encodes the training data. Successively more general models are produced by merging HMM states. A Bayesian posterior probability criterion is used to determine which states to merge and when to stop generalizing. The procedure may be considered a heuristic search for the HMM structure with the highest posterior probability. We discuss a variety of possible priors for HMMs, as well as a number of approximations which improve the computational efficiency of the algorithm. We studied three applications to evaluate the procedure. The first compares the merging algorithm with the standard Baum-Welch approach in inducing simple finite-state languages from small, positive-only training samples. We found that the merging procedure is more robust and accurate, particularly with a small amount of training data. The second application uses labelled speech data from the TIMIT database to build compact, multiple-pronunciation word models that can be used in speech recognition. Finally, we describe how the algorithm was incorporated in an operational speech understanding system, where it is combined with neural network acoustic likelihood estimators to improve performance over single-pronunciation word models.