 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiential Explanations for Reinforcement Learning
Paper and Code

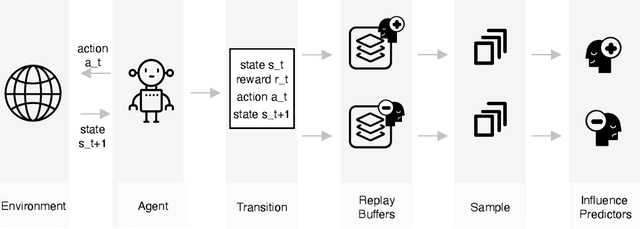

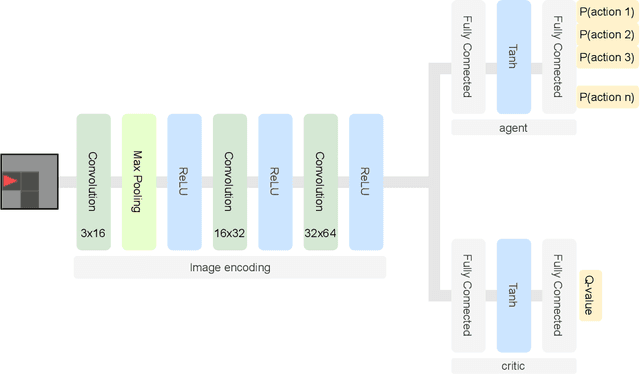
Reinforcement Learning (RL) approaches are becoming increasingly popular in various key disciplines, including robotics and healthcare. However, many of these systems are complex and non-interpretable, making it challenging for non-AI experts to understand or intervene. One of the challenges of explaining RL agent behavior is that, when learning to predict future expected reward, agents discard contextual information about their experiences when training in an environment and rely solely on expected utility. We propose a technique, Experiential Explanations, for generating local counterfactual explanations that can answer users' why-not questions by explaining qualitatively the effects of the various environmental rewards on the agent's behavior. We achieve this by training additional modules alongside the policy. These models, called influence predictors, model how different reward sources influence the agent's policy, thus restoring lost contextual information about how the policy reflects the environment. To generate explanations, we use these models in addition to the policy to contrast between the agent's intended behavior trajectory and a counterfactual trajectory suggested by the user.