 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Referring Expression Comprehension via Transformer with Content-aware Query
Paper and Code
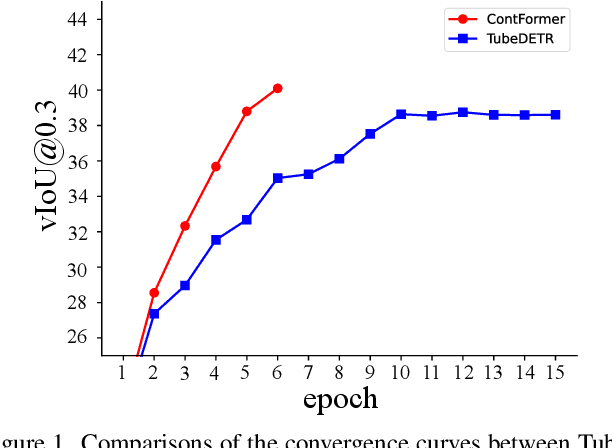
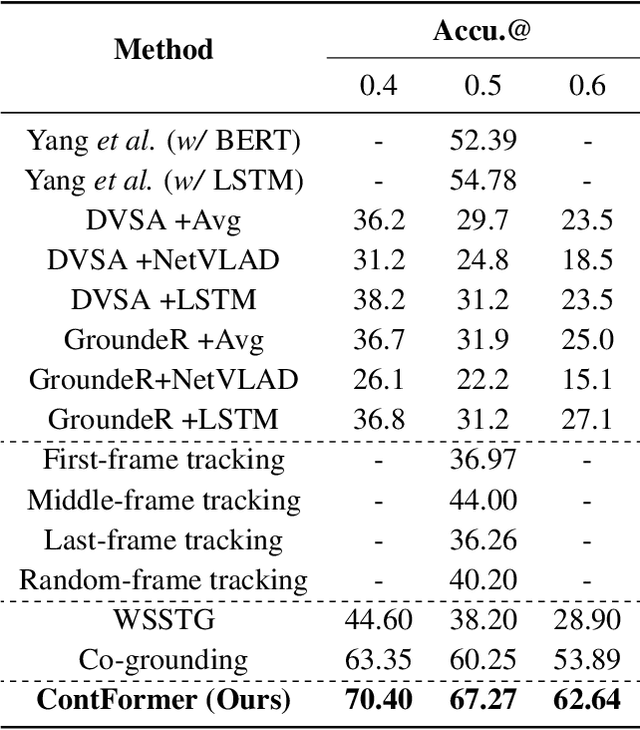

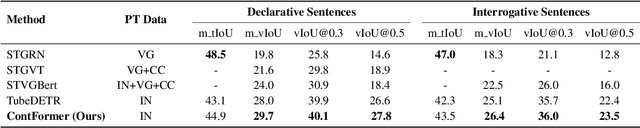
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.