 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Text Augmentation with Word Roles for Low-Resource Text Classification
Paper and Code
Sep 04, 2022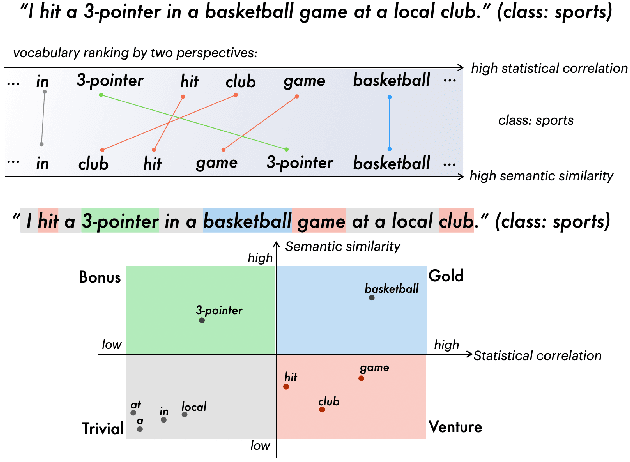

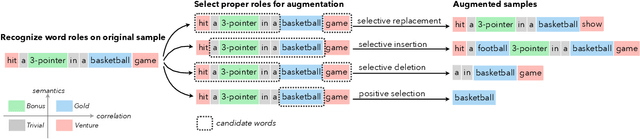
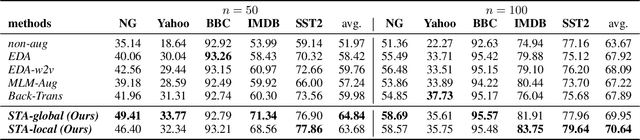
Data augmentation techniques are widely used in text classification tasks to improve the performance of classifiers, especially in low-resource scenarios. Most previous methods conduct text augmentation without considering the different functionalities of the words in the text, which may generate unsatisfactory samples. Different words may play different roles in text classification, which inspires us to strategically select the proper roles for text augmentation. In this work, we first identify the relationships between the words in a text and the text category from the perspectives of statistical correlation and semantic similarity and then utilize them to divide the words into four roles -- Gold, Venture, Bonus, and Trivial words, which have different functionalities for text classification. Based on these word roles, we present a new augmentation technique called STA (Selective Text Augmentation) where different text-editing operations are selectively applied to words with specific roles. STA can generate diverse and relatively clean samples, while preserving the original core semantics, and is also quite simple to implement. Extensive experiments on 5 benchmark low-resource text classification datasets illustrate that augmented samples produced by STA successfully boost the performance of classification models which significantly outperforms previous non-selective methods, including two large language model-based techniques. Cross-dataset experiments further indicate that STA can help the classifiers generalize better to other datasets than previous methods.