 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
Paper and Code
Jul 28, 2022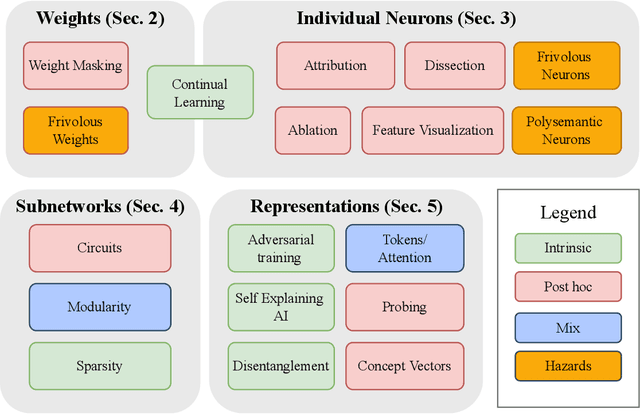
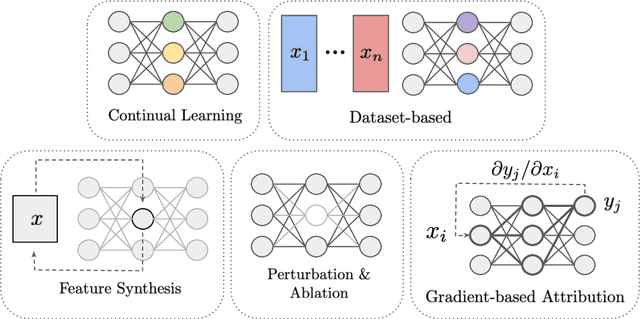
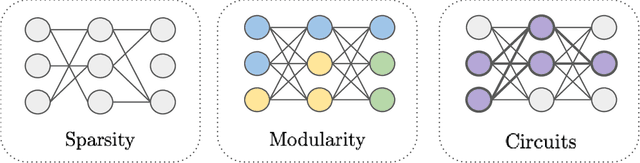
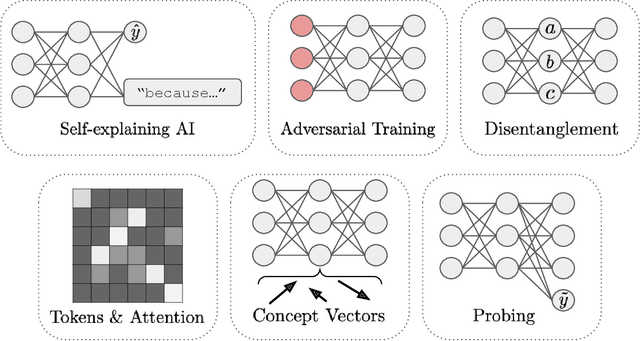
The last decade of machine learning has seen drastic increases in scale and capabilities, and deep neural networks (DNNs) are increasingly being deployed across a wide range of domains. However, the inner workings of DNNs are generally difficult to understand, raising concerns about the safety of using these systems without a rigorous understanding of how they function. In this survey, we review literature on techniques for interpreting the inner components of DNNs, which we call "inner" interpretability methods. Specifically, we review methods for interpreting weights, neurons, subnetworks, and latent representations with a focus on how these techniques relate to the goal of designing safer, more trustworthy AI systems. We also highlight connections between interpretability and work in modularity, adversarial robustness, continual learning, network compression, and studying the human visual system. Finally, we discuss key challenges and argue for future work in interpretability for AI safety that focuses on diagnostics, benchmarking, and robustness.