 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Efficient Segmentation of Cross-domain Medical Images
Paper and Code
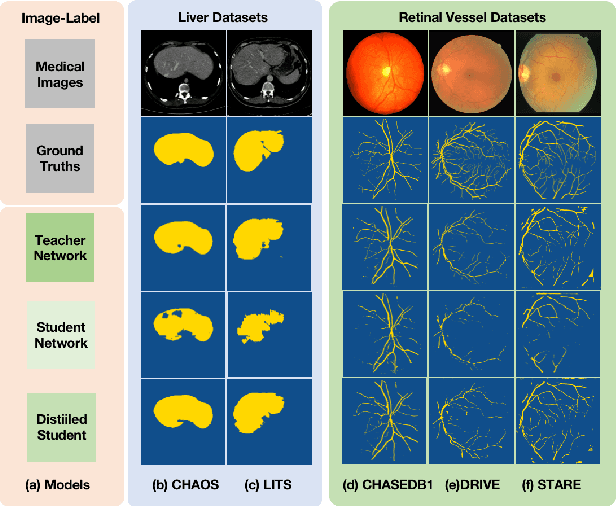
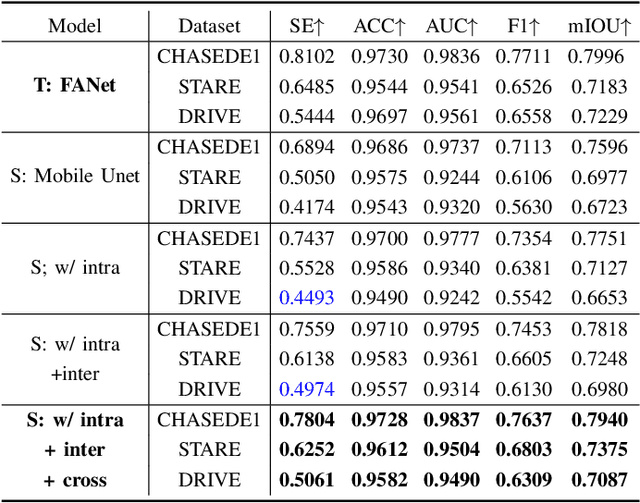
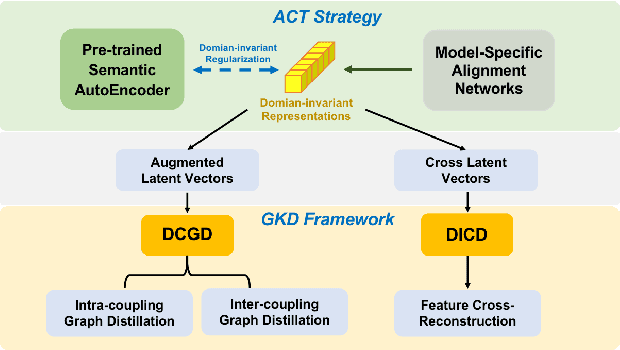
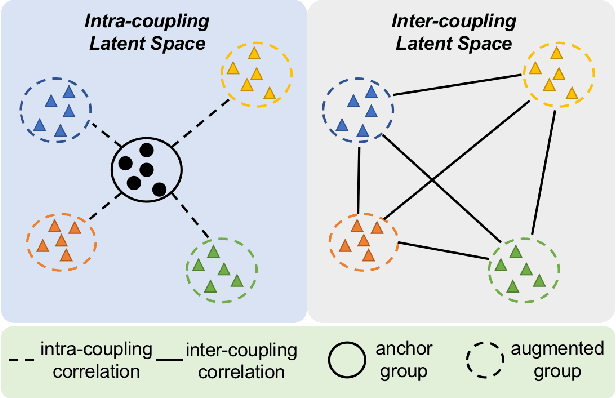
Efficient medical image segmentation aims to provide accurate pixel-wise prediction for the medical images with the lightweight implementation framework. However, lightweight frameworks generally fail to achieve high performance, and suffer from the poor generalizable ability on cross-domain tasks.In this paper, we propose a generalizable knowledge distillation method for robust and efficient segmentation of cross-domain medical images. Primarily, we propose the Model-Specific Alignment Networks (MSAN) to provide the domain-invariant representations which are regularized by a Pre-trained Semantic AutoEncoder (P-SAE). Meanwhile, a customized Alignment Consistency Training (ACT) strategy is designed to promote the MSAN training. With the domain-invariant representative vectors in MSAN, we propose two generalizable knowledge distillation schemes, Dual Contrastive Graph Distillation (DCGD) and Domain-Invariant Cross Distillation (DICD). Specifically, in DCGD, two types of implicit contrastive graphs are designed to represent the intra-coupling and inter-coupling semantic correlations from the perspective of data distribution. In DICD, the domain-invariant semantic vectors from the two models (i.e., teacher and student) are leveraged to cross-reconstruct features by the header exchange of MSAN, which achieves generalizable improvement for both the encoder and decoder in the student model. Furthermore, a metric named Fr\'echet Semantic Distance (FSD) is tailored to verify the effectiveness of the regularized domain-invariant features. Extensive experiments conducted on the Liver and Retinal Vessel Segmentation datasets demonstrate the priority of our method, in terms of performance and generalization on lightweight frameworks.