 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoInit: Automatic Initialization via Jacobian Tuning
Paper and Code
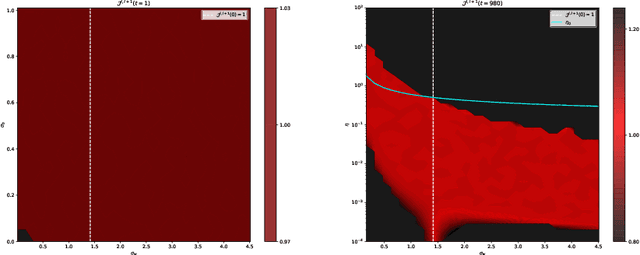
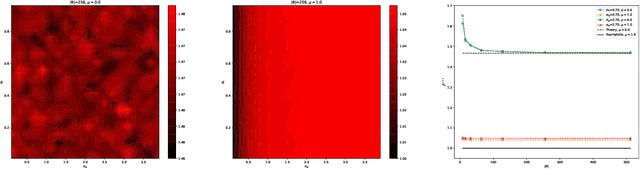
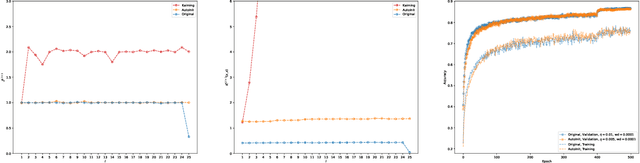
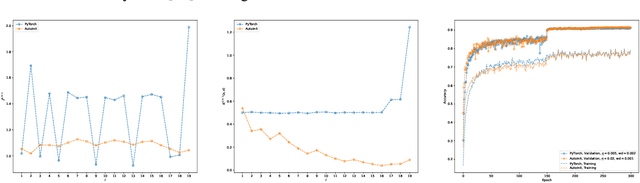
Good initialization is essential for training Deep Neural Networks (DNNs). Oftentimes such initialization is found through a trial and error approach, which has to be applied anew every time an architecture is substantially modified, or inherited from smaller size networks leading to sub-optimal initialization. In this work we introduce a new and cheap algorithm, that allows one to find a good initialization automatically, for general feed-forward DNNs. The algorithm utilizes the Jacobian between adjacent network blocks to tune the network hyperparameters to criticality. We solve the dynamics of the algorithm for fully connected networks with ReLU and derive conditions for its convergence. We then extend the discussion to more general architectures with BatchNorm and residual connections. Finally, we apply our method to ResMLP and VGG architectures, where the automatic one-shot initialization found by our method shows good performance on vision tasks.