 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of the composition of feature extraction and class sampling in medicare fraud detection
Paper and Code
Jun 03, 2022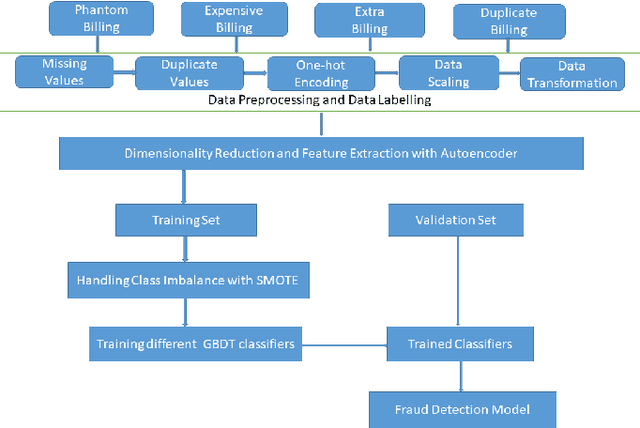
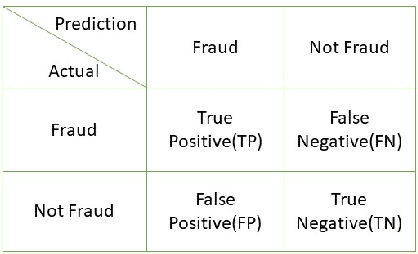
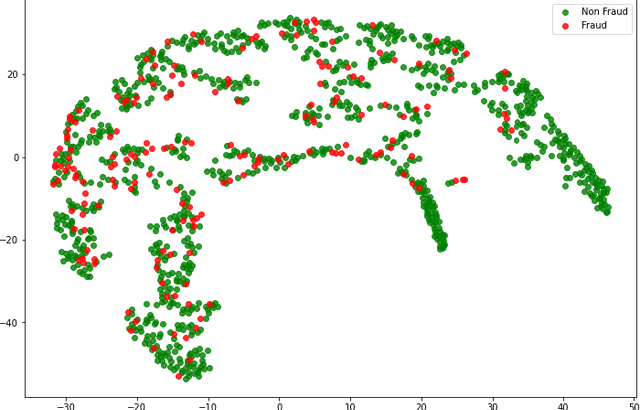
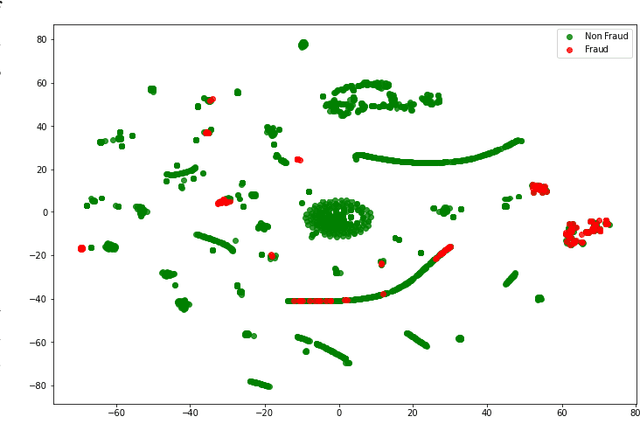
With healthcare being critical aspect, health insurance has become an important scheme in minimizing medical expenses. Following this, the healthcare industry has seen a significant increase in fraudulent activities owing to increased insurance, and fraud has become a significant contributor to rising medical care expenses, although its impact can be mitigated using fraud detection techniques. To detect fraud, machine learning techniques are used. The Centers for Medicaid and Medicare Services (CMS) of the United States federal government released "Medicare Part D" insurance claims is utilized in this study to develop fraud detection system. Employing machine learning algorithms on a class-imbalanced and high dimensional medicare dataset is a challenging task. To compact such challenges, the present work aims to perform feature extraction following data sampling, afterward applying various classification algorithms, to get better performance. Feature extraction is a dimensionality reduction approach that converts attributes into linear or non-linear combinations of the actual attributes, generating a smaller and more diversified set of attributes and thus reducing the dimensions. Data sampling is commonlya used to address the class imbalance either by expanding the frequency of minority class or reducing the frequency of majority class to obtain approximately equal numbers of occurrences for both classes. The proposed approach is evaluated through standard performance metrics. Thus, to detect fraud efficiently, this study applies autoencoder as a feature extraction technique, synthetic minority oversampling technique (SMOTE) as a data sampling technique, and various gradient boosted decision tree-based classifiers as a classification algorithm. The experimental results show the combination of autoencoders followed by SMOTE on the LightGBM classifier achieved best results.